
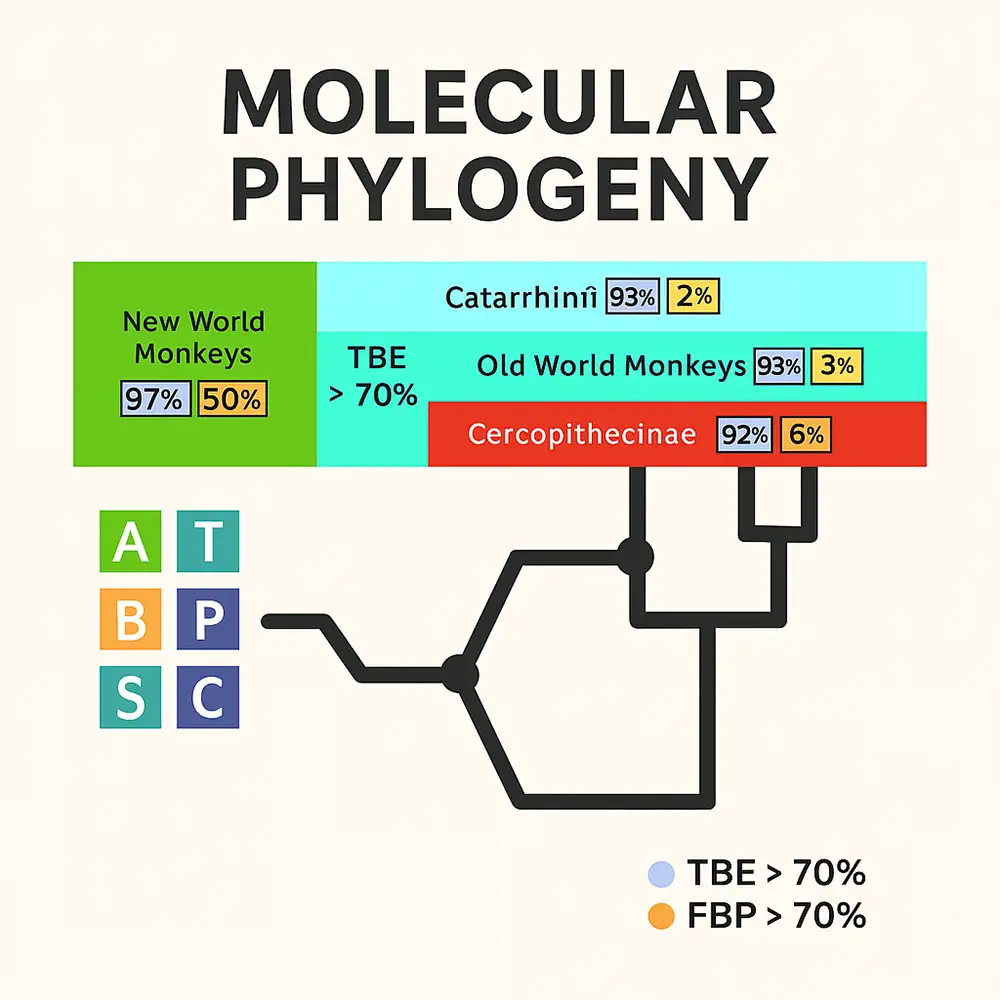
بوت استرپ Bootstrap در آنالیز تبارزایی چیست؟
تحلیل فیلوژنتیک و اهمیت آن
تحلیل فیلوژنتیک به مطالعهی روابط تکاملی میان جانداران، ژنها یا پروتئینها گفته میشود که معمولاً در قالب نمودارهای شاخهای به نام درختهای فیلوژنتیک نمایش داده میشوند. این درختها صرفاً ساختارهای انتزاعی نیستند، بلکه فرضیههای قدرتمندی دربارهی تاریخ حیات هستند و به دانشمندان کمک میکنند تا الگوهای واگرایی، نیای مشترک و سازگاریها را درک کنند.
در زیستشناسی تکاملی، چنین تحلیلهایی چارچوبی برای ردهبندی تنوع زیستی، ردیابی خاستگاه صفات و آزمون فرضیهها دربارهی چگونگی تکامل جانداران فراهم میکنند. در حوزههای کاربردی نیز روشهای فیلوژنتیک اهمیت زیادی دارند:
-
در پزشکی و اپیدمیولوژی، برای ردیابی گسترش بیماریهای عفونی استفاده میشوند.
-
در زیستشناسی حفاظت، برای شناسایی دودمانهای تکاملی متمایز که نیازمند حفاظت هستند به کار میروند.
-
در کشاورزی، برای بازسازی تاریخ اهلیسازی محصولات کشاورزی مورد استفاده قرار میگیرند.
به همین دلیل، قابلیت اعتماد درختهای فیلوژنتیک اهمیت بنیادی دارد.
چالش قابلیت اعتماد درختها
با وجود پیشرفتهای چشمگیر در فناوریهای توالییابی و روشهای محاسباتی، ساخت درختهای فیلوژنتیک همچنان کار سادهای نیست. تکامل تنها شواهد غیرمستقیم بهجا گذاشته است، مانند توالیهای DNA، ساختارهای پروتئینی یا ویژگیهای ریختشناسی. پژوهشگران باید از این دادهها، تاریخ شاخهبندیهایی را بازسازی کنند که ممکن است صدها میلیون سال را در بر گیرد.
اما به دلیل پیچیدگی تکامل و محدودیتهای مجموعه دادهها، هیچ درختی هرگز کاملاً قطعی نیست. در عوض، هر بازسازی فیلوژنتیک یک برآورد است که به انتخاب دادهها، روشهای تحلیلی و مدلهای تکاملی زیربنایی حساسیت دارد. این عدم قطعیت ذاتی پرسش مهمی را مطرح میکند:
دانشمندان تا چه حد میتوانند به شاخهها یا کلادهای یک درخت فیلوژنتیک اعتماد کنند؟
پاسخ به این پرسش نیازمند ابزارهای آماری برای سنجش میزان پشتیبانی از روابط بازسازیشده است. یکی از نخستین و تأثیرگذارترین این ابزارها، بوتاسترپ (Bootstrap) است.
بوتاسترپ (Bootstrap) در آنالیز تبارزایی چیست؟
بوتاسترپ یک روش آماری است که برای سنجش میزان اطمینان (Confidence) در شاخههای یک درخت تبارزایی (Phylogenetic Tree) استفاده میشود.
در آنالیز تبارزایی، دانشمندان معمولاً با ماتریس دادهای کار میکنند (مثلاً یک همردیفی از توالیهای DNA، RNA یا پروتئین). از این دادهها درختی ساخته میشود که نشان میدهد موجودات یا ژنها چطور با هم خویشاوندی دارند.
اما سؤال مهم این است:
آیا شاخههای این درخت واقعاً قابل اعتمادند یا حاصل نویز و تصادف در دادهها هستند؟
اینجاست که بوتاسترپ وارد میشود.
مراحل سادهی بوتاسترپ در فیلوژنی:
-
از ماتریس دادهی اصلی (مثلاً همردیفی توالیها)، نمونهبرداری تصادفی با جایگزینی انجام میشود.
-
یعنی ستونهای همردیفی (مکانهای ژنتیکی) به طور تصادفی انتخاب میشن و یک ماتریس جدید به همان اندازه ساخته میشه.
-
به این ماتریس جدید میگن pseudo-replicate dataset (مجموعهدادهی شبهتکراری).
-
-
با این دادهی جدید، درخت تبارزایی دوباره ساخته میشود.
-
این کار معمولاً صدها یا هزاران بار تکرار میشود (مثلاً 1000 بار).
-
در پایان، برای هر شاخهی درخت اصلی بررسی میشود که چند درصد از درختهای بوتاسترپ آن شاخه را دوباره بازسازی کردهاند.
مثال:
-
فرض کن درخت اصلی نشان میدهد گونههای A و B با هم یک شاخه (Clade) تشکیل میدهند.
-
بعد از 1000 بار بوتاسترپ، اگر در 850 بار همین شاخه دوباره ظاهر شد، مقدار بوتاسترپ آن شاخه 85٪ خواهد بود.
تفسیر مقادیر بوتاسترپ:
-
کمتر از 50٪ → شاخه ضعیف و غیرقابل اعتماد است.
-
70٪ به بالا → معمولاً به عنوان حمایت متوسط در نظر گرفته میشود.
-
90–95٪ به بالا → حمایت قوی و تقریباً قابل اعتماد.
بوتاسترپ در آمار
بوتاسترپ یک روش بازنمونهگیری آماری عمومی است که نخستین بار توسط بردلی افرون (Bradley Efron) در سال 1979 معرفی شد. ایدهی اصلی آن ساده و قدرتمند است:
بهجای تکیه صرف بر توزیعهای احتمالی نظری، پژوهشگران میتوانند با بازنمونهگیری مکرر از دادههای خود، قابلیت اعتماد یک آماره را برآورد کنند.
در این روش:
-
مجموعه دادههای «شبه» (pseudo-datasets) به اندازهی مجموعهی اصلی و با نمونهگیری با جایگزینی ساخته میشوند.
-
سپس آمارهی مورد نظر برای هزاران مجموعه شبهداده محاسبه میشود.
-
بدین ترتیب، پژوهشگران میتوانند توزیع آن آماره و میزان تغییرپذیریاش را تخمین بزنند.
این روش یک رویکرد انعطافپذیر و مبتنی بر دادهها برای برآورد بازههای اطمینان، آزمون فرضیهها و سنجش استحکام یافتهها در حوزههای مختلف علمی ارائه میدهد.
انطباق بوتاسترپ برای فیلوژنتیک
در سال 1985، جوزف فِلزنشتاین (Joseph Felsenstein) بوتاسترپ را وارد حوزهی فیلوژنتیک کرد و بدین ترتیب روشی تحولآفرین برای ارزیابی قابلیت اعتماد توپولوژی درختها ایجاد شد.
در این نسخه:
-
بهجای بازنمونهگیری کل مشاهدات، ویژگیها (Characters) بازنمونهگیری میشوند.
-
این ویژگیها میتوانند مکانهای نوکلئوتیدی در یک همترازی توالی DNA باشند.
-
با بازنمونهگیری این ویژگیها همراه با جایگزینی، پژوهشگران شبههمترازیهای متعددی ایجاد میکنند.
-
سپس برای هر شبههمترازی یک درخت بازسازی میشود.
-
در نهایت، فراوانی ظاهر شدن هر شاخه یا کلاد در میان مجموعهای از درختها محاسبه میشود.
این فراوانی به صورت درصد بوتاسترپ بیان میشود و نشاندهندهی سطح پشتیبانی دادهها از آن شاخه است.
این انطباق انقلابی در زیستشناسی تکاملی ایجاد کرد، زیرا راهی برای کمیسازی اعتماد به فرضیههای فیلوژنتیک فراهم آورد، کاری که پیشتر بسیار دشوار بود.
نقش بوتاسترپ در فیلوژنتیک مدرن
از زمان معرفی، بوتاسترپ به یکی از پرکاربردترین روشها برای ارزیابی درختهای فیلوژنتیک بدل شده است.
امروزه:
-
از آن در مطالعات کوچک (درختهای ژنی) تا پروژههای عظیم فیلوژنومیک با هزاران ژن و صدها تاکسون استفاده میشود.
-
مجلات علمی، داوران و کنفرانسهای تخصصی اغلب گزارش درصد بوتاسترپ را همراه با درختها ضروری میدانند.
-
با وجود توسعهی روشهای جدیدتر مثل احتمال پسین بیزی (Bayesian Posterior Probabilities) یا آزمونهای مبتنی بر درستنمایی (Likelihood Tests)، بوتاسترپ همچنان به دلیل سادگی مفهومی، کاربرد وسیع و میراث تاریخی خود تأثیرگذار باقی مانده است.
به همین دلیل، درک بوتاسترپ برای هر پژوهشگر فعال در فیلوژنتیک – چه در زیستشناسی تکاملی، ژنومیک، پزشکی یا بومشناسی – ضروری است.
بخش دوم: پیشینه تاریخی
چالشهای اولیه در اعتماد به درختهای فیلوژنتیک
پیش از معرفی روشهای بوتاسترپ، زیستشناسان تکاملی با موانع قابلتوجهی در کمیسازی میزان اطمینان به درختهای فیلوژنتیک روبهرو بودند. در میانه قرن بیستم، بیشتر مطالعات فیلوژنتیک بر ویژگیهای مورفولوژیک یا دادههای مولکولی محدود (مانند توالی پروتئینها) متکی بودند. خود روشهای فیلوژنتیک نیز در حال توسعه سریع بودند و رویکردهایی چون پارسیمنی (Parsimony)، روشهای فاصلهای (Distance Methods) و نخستین روشهای مبتنی بر درستنمایی (Likelihood-based Approaches) مورد بررسی قرار میگرفتند.
با این حال، هرچند این روشها میتوانستند درختهایی بسازند، هیچ چارچوب آماری پذیرفتهشدهای وجود نداشت که مشخص کند تا چه حد میتوان به الگوهای شاخهبندی اعتماد کرد. درختها اغلب به گونهای ارائه میشدند که گویی قطعی هستند، اما در واقعیت، تغییرات اندک در دادهها یا در فرضیات تحلیلی میتوانستند توپولوژیهای بسیار متفاوتی ایجاد کنند. پژوهشگران بهخوبی از این عدم قطعیت آگاه بودند، اما ابزاری رسمی برای اندازهگیری آن نداشتند.
ظهور بازنمونهگیری آماری در دهه ۱۹۷۰
در عرصه آمار، دهه ۱۹۷۰ دورهای بود که نوآوریهای خلاقانه در روشهای بازنمونهگیری (Resampling Methods) شکل گرفت. روشهایی چون Jackknife، Cross-validation (اعتبارسنجی متقابل) و Randomization tests (آزمونهای تصادفیسازی) برای غلبه بر محدودیتهای آمار کلاسیک پارامتریک معرفی شدند.
در میان این نوآوریها، توسعه روش بوتاسترپ (Bootstrap) توسط بردلی افرون (Bradley Efron) در سال ۱۹۷۹ نقطه عطفی به شمار میرفت. بینش اصلی افرون این بود که دادههای تجربی خود میتوانند نقش توزیع احتمالی را ایفا کنند: با بازنمونهگیری مکرر از دادهها با جایگزینی (Sampling with replacement)، میتوان شبهنمونههایی (Pseudo-replicates) ایجاد کرد که تغییرپذیری ذاتی مجموعهداده را بازتاب میدهند.
این رویکرد به پژوهشگران امکان داد تا فواصل اطمینان و توزیع خطاها را بدون نیاز به مدلهای نظری سخت به دست آورند. بوتاسترپ بهسرعت در حوزههای متنوعی از جمله اقتصادسنجی تا پژوهشهای پزشکی به عنوان ابزاری همهکاره برای سنجش پایداری نتایج شناخته شد.
مشارکت فِلسنشتاین در سال ۱۹۸۵
انطباق بوتاسترپ با فیلوژنتیک به جوزف فِلسنشتاین (Joseph Felsenstein) نسبت داده میشود که در مقاله تاریخی سال ۱۹۸۵ خود این روش را وارد زیستشناسی تکاملی کرد.
فلسنشتاین دریافت که کاراکترها (Characters) – چه ویژگیهای مورفولوژیک باشند و چه مکانهای نوکلئوتیدی در یک همترازی توالی (Sequence Alignment) – همانند مشاهدات در آمار سنتی هستند. او نشان داد که با بازنمونهگیری از این کاراکترها با جایگزینی، ایجاد شبهمجموعهدادهها و بازسازی درخت از هرکدام، میتوان توزیعی از درختها به دست آورد که عدم قطعیت موجود در دادهها را منعکس میکند.
سپس، نسبتی از دفعاتی که یک کلاد (Clade) خاص در میان این تکرارها ظاهر میشود، به عنوان معیاری از میزان پشتیبانی دادهها از آن کلاد تفسیر میگردد. نوآوری فلسنشتاین راهحلی عملی و مبتنی بر آمار برای مسئله دیرینه اعتماد به درختهای فیلوژنتیک ارائه داد. سادگی و عمومی بودن روش، آن را برای جامعه گستردهای از زیستشناسان در دسترس ساخت و انتشار مقاله او بلافاصله توجه بسیاری را جلب کرد.
پذیرش اولیه و تأثیر
معرفی روش بوتاسترپ در فیلوژنتیک با شور و هیجان و البته با احتیاط مواجه شد. بسیاری از پژوهشگران از امکان الصاق مقادیر کمی پشتیبانی به شاخههای درختها استقبال کردند، چرا که این کار، درختهای فیلوژنتیک را از نمودارهایی موقتی به فرضیههایی آگاه از آمار تبدیل میکرد.
مقادیر بوتاسترپ بهسرعت به ویژگی استاندارد در انتشارات فیلوژنتیک تبدیل شدند و زبانی برای مقایسه میزان پایداری کلادهای رقیب فراهم کردند.
با این حال، بحثهایی نیز در گرفت:
-
آیا درصد بوتاسترپ نمایانگر احتمال واقعی درستی یک کلاد است؟
-
یا صرفاً معیاری است از اینکه دادهها تا چه حد بهطور پایدار از آن کلاد در بازنمونهگیری پشتیبانی میکنند؟
این پرسشها پیشدرآمد چالشهای تفسیری بودند که تا امروز هم ادامه یافتهاند، اما مانع از پذیرش گسترده بوتاسترپ بهعنوان یک ابزار اساسی نشدند.
گسترش کاربرد در عصر مولکولی
اواخر دهه ۱۹۸۰ و اوایل دهه ۱۹۹۰ با رشد سریع فیلوژنتیک مولکولی همراه بود که محرک آن پیشرفتهای فناوری در توالییابی DNA بود. با در دسترس بودن مجموعهدادههای بزرگتر، نیاز به روشهایی قابلاعتماد برای ارزیابی اطمینان درختها بیش از پیش احساس میشد.
تحلیل بوتاسترپ بهطور طبیعی در این زمینه جا افتاد: این روش را میشد بر همترازیهای DNA، RNA یا پروتئینها به کار برد، صرفنظر از اندازه یا پیچیدگی آنها. بستههای نرمافزاری مانند PHYLIP (که توسط خود فلسنشتاین توسعه یافت) استفاده از بوتاسترپ را برای جامعه جهانی زیستشناسان فراهم ساختند.
با ظهور روشهای درستنمایی بیشینه (Maximum Likelihood) در دهه ۱۹۹۰ و بعدها استنباط بیزی (Bayesian Inference) در دهه ۲۰۰۰، بوتاسترپ همچنان جایگاه خود را به عنوان یک روش معیار (Benchmark) حفظ کرد و اغلب در کنار یا برای مقایسه با روشهای جدیدتر مورد استفاده قرار گرفت.
بحثها و اصلاحات
با جاافتادن بوتاسترپ در فیلوژنتیک، بحثهای روششناختی نیز شکل گرفت. برخی پژوهشگران استدلال کردند که مقادیر بوتاسترپ بیش از حد محافظهکارانهاند و تمایل به دستکم گرفتن اعتماد دارند، بهویژه در مقایسه با احتمالهای پسین بیزی (Bayesian Posterior Probabilities).
دیگران هشدار دادند که مقادیر بوتاسترپ ممکن است در شرایط خاصی گمراهکننده باشند، مانند:
-
جاذبه شاخههای بلند (Long-branch attraction)
-
یا زمانی که دادهها اندک و ناکافی باشند.
این چالشها باعث شد اصلاحاتی ایجاد شود، از جمله:
-
بوتاسترپ پارامتریک (Parametric Bootstrap)
-
تحلیلهای تقسیمبندیشده (Partitioned Analyses)
-
و بهبود الگوریتمها برای محاسبات سریعتر.
تا اوایل دهه ۲۰۰۰، تحلیل بوتاسترپ بهشدت در عمل فیلوژنتیک تثبیت شده بود، اما همراه با آن درک پیچیدهتری از محدودیتها و شرایط استفاده محتاطانه نیز به وجود آمد.
بوتاسترپ در عصر فیلوژنومیک
قرن بیستویکم شاهد انفجار دادهها بوده است، بهطوری که مطالعات فیلوژنومیک (Phylogenomics) اکنون صدها یا هزاران ژن را بهطور همزمان تحلیل میکنند.
این مقیاس عظیم دادهها نیازهای تازهای به روشهای محاسباتی تحمیل کرده است و به توسعه الگوریتمهای سریعتر بوتاسترپ در نرمافزارهایی مانند RAxML، IQ-TREE و PhyML منجر شده است. این پیشرفتها به پژوهشگران امکان دادهاند تحلیل بوتاسترپ را بر مجموعهدادههایی با اندازه بیسابقه اعمال کنند و بدین ترتیب، این روش حتی در عصر ژنومیک نیز همچنان مرتبط باقی بماند.
در همین حال، میراث تاریخی مقاله ۱۹۸۵ فلسنشتاین همچنان گرامی داشته میشود و بوتاسترپ اغلب بهعنوان یکی از اثرگذارترین مشارکتهای روششناختی در زیستشناسی تکاملی توصیف میشود.
بخش سوم: مبانی نظری بوتاسترپ
منطق بازنمونهگیری در آمار
بوتاسترپ بخشی از خانوادهای از تکنیکهای آماری است که بر بازنمونهگیری (Resampling) برای تقریب توزیع یک آمار (Statistic) تکیه دارند.
در رویکردهای پارامتریک سنتی، فواصل اطمینان یا خطاهای استاندارد از توزیعهای احتمالی شناختهشده (مثل توزیع نرمال) و تحت فرضهایی درباره فرآیند تولید داده به دست میآیند. با این حال، دادههای زیستی – بهویژه دادههای فیلوژنتیک – اغلب این فرضیات را به دلیل پیچیدگی و وابستگیهای درونی نقض میکنند.
بوتاسترپ این محدودیتها را دور میزند، چرا که مستقیماً از دادههای مشاهدهشده بازنمونهگیری میکند، نه اینکه توزیع نظری خارجی بر آن تحمیل کند. با تولید تعداد زیادی شبهمجموعهداده (Pseudo-dataset) از طریق نمونهگیری با جایگزینی، میتوان توزیع تجربی آماری مورد نظر را ساخت؛ سپس از این توزیع برای برآورد تغییرپذیری، بایاس (Bias) یا فواصل اطمینان استفاده کرد.
این منطق، بوتاسترپ را بسیار سازگار و منعطف میسازد، بهویژه در حوزههایی که مدلهای نظری ناکافی یا بیش از حد محدودکنندهاند.
بوتاسترپ ناپارامتریک و پارامتریک
دو دسته کلی از بوتاسترپ وجود دارد: ناپارامتریک و پارامتریک.
-
بوتاسترپ ناپارامتریک که توسط افرون معرفی شد، مستقیماً از داده اصلی با جایگزینی نمونهگیری میکند و شبهنمونههایی ایجاد میکند که بازتابی از تغییرپذیری ذاتی دادهها هستند.
-
در فیلوژنتیک، این معادل بازنمونهگیری از کاراکترها (Characters) مانند مکانهای نوکلئوتیدی، کدونها یا ویژگیهای مورفولوژیک است.
-
-
بوتاسترپ پارامتریک در مقابل، فرض میکند که یک مدل تکاملی خاص برقرار است و بر اساس آن مدل مجموعهدادههای شبیهسازیشده تولید میکند. سپس این مجموعهها مانند داده اصلی تحلیل میشوند و تنوع میان آنها معیاری از اطمینان فراهم میآورد.
در حالی که بوتاسترپ ناپارامتریک به دلیل عدم وابستگی به مدل بیشتر استفاده میشود، بوتاسترپ پارامتریک برای آزمون فرضیههای تکاملی خاص (مثلاً احتمال رخداد جاذبه شاخههای بلند – Long-branch Attraction) ارزشمند بوده است.
این تمایز نشاندهنده انعطافپذیری بوتاسترپ در مواجهه با چالشهای استنباطی مختلف است.
بوتاسترپ و برآورد اطمینان
یکی از جذابیتهای اصلی بوتاسترپ، توانایی آن در تقریب میزان اطمینان به یک نتیجه بدون نیاز به استنتاجهای تحلیلی پیچیده است.
در آمار، توزیعهای بوتاسترپشده میتوانند برای ساختن فواصل اطمینان تقریباً برای هر برآوردگری (Estimator) استفاده شوند، حتی زمانی که توزیع نظری آن ناشناخته یا پیچیده باشد.
در فیلوژنتیک، مشابه آن مقادیر پشتیبانی بوتاسترپ (Bootstrap Support Values) هستند که معمولاً به صورت درصد بیان میشوند و نشان میدهند که یک کلاد خاص چند بار در میان تکرارهای بوتاسترپ بازیابی شده است.
-
اگر کلادی در ۹۵٪ از درختهای بوتاسترپ ظاهر شود، بسیار پایدار در نظر گرفته میشود.
-
اگر تنها در ۵۰٪ از آنها دیده شود، ضعیف پشتیبانی میشود.
با این حال، باید توجه داشت که مقادیر بوتاسترپ معادل مستقیم فواصل اطمینان کلاسیک یا احتمالهای پسین بیزی نیستند. آنها در واقع معیارهایی از سازگاری (Consistency) هستند که نشان میدهند دادههای مشاهدهشده تا چه حد از یک کلاد در بازنمونهگیری حمایت میکنند.
فرض استقلال کاراکترها
یکی از مسائل نظری کلیدی در بوتاسترپ فیلوژنتیک، فرض استقلال کاراکترها است.
روش بوتاسترپ هر کاراکتر – چه یک سایت DNA، یک اسید آمینه یا یک ویژگی مورفولوژیک – را به عنوان یک مشاهده مستقل در نظر میگیرد که میتواند بازنمونهگیری شود.
اما در واقعیت، فرآیندهای تکاملی اغلب همبستگی (Correlation) میان کاراکترها ایجاد میکنند:
-
مثلاً سایتهای نوکلئوتیدی یک ژن ممکن است عدم تعادل پیوندی (Linkage Disequilibrium) نشان دهند.
-
یا ویژگیهای مورفولوژیک میتوانند تحت محدودیتهای رشدی باشند.
این همبستگیها بدین معناست که کاراکترها کاملاً مستقل نیستند و همین امر تفسیر مقادیر بوتاسترپ را پیچیده میسازد.
با این وجود، بوتاسترپ همچنان مفید باقی میماند، زیرا فرایند بازنمونهگیری بخش زیادی از ساختار کلی دادهها را حفظ میکند و مقادیر حاصل، همچنان شاخصهایی تقریبی اما معنادار از قابلیت اعتماد هستند.
این تنش میان فرض استقلال و پیچیدگی دادههای زیستی یادآور این است که مقادیر بوتاسترپ باید با احتیاط تفسیر شوند و نباید آنها را به عنوان احتمالات دقیق در نظر گرفت.
بوتاسترپ و توزیع درختها
یکی دیگر از پایههای نظری تحلیل بوتاسترپ، توانایی آن در تقریب توزیع توپولوژیهای درختی است.
در آمار کلاسیک، بوتاسترپ برای تقریب توزیع نمونهگیری یک پارامتر استفاده میشود.
اما در فیلوژنتیک، شیء مورد استنباط یک پارامتر منفرد نیست، بلکه کل درخت است – که نهادی بسیار پیچیده و چندبعدی است.
-
بازنمونهگیریهای بوتاسترپ مجموعهای از درختها تولید میکنند که هر کدام به دلیل تغییرات بازنمونهگیری اندکی متفاوتاند.
-
با گردآوری این درختها میتوان تخمین زد که گروهبندیها یا کلادها تا چه اندازه در برابر خطاهای نمونهگیری پایدارند.
این دیدگاه توزیعی بسیار مهم است: بوتاسترپ بهجای اینکه تنها یک "درخت واقعی" بسازد، تصدیق میکند که دادهها ذاتاً دارای نویز هستند و درختهای معقول متعددی ممکن است وجود داشته باشند.
بنابراین، فراوانی کلادها در تکرارهای بوتاسترپ روشی عملی برای خلاصه کردن این عدم قطعیت فراهم میکند.
برداشتهای نادرست درباره مقادیر بوتاسترپ
یکی از سوءتفاهمهای رایج در فیلوژنتیک این است که درصد بوتاسترپ معادل احتمال درستی یک کلاد است.
در واقع چنین نیست:
-
یک مقدار بوتاسترپ ۹۵٪ به این معنا نیست که ۹۵٪ احتمال دارد آن کلاد بازتابدهنده تاریخ تکاملی واقعی باشد.
-
بلکه یعنی در ۹۵٪ از بازنمونهگیریهای بوتاسترپ، آن کلاد تحت روش استنباط انتخابشده بازیابی شده است.
این تفاوت ظریف اما مهم پیامدهای تفسیری قابلتوجهی دارد.
مقادیر بوتاسترپ تحت تأثیر عواملی چون:
-
اندازه مجموعهداده،
-
مشخصات مدل،
-
و وجود بایاسهای نظاممند،
قرار میگیرند.
بنابراین:
-
مقادیر بالای بوتاسترپ گاهی میتوانند گمراهکننده باشند، اگر دادهها بایاسدار یا ناکافی باشند.
-
در مقابل، مقادیر پایین بوتاسترپ لزوماً به معنای نادرستی یک کلاد نیستند؛ بلکه ممکن است نشاندهنده اطلاعات ناکافی باشند.
بوتاسترپ بهعنوان ابزاری فرکانسی
بوتاسترپ اساساً یک روش فرکانسی (Frequentist) است که بر منطق نمونهگیری مکرر بنا شده است.
هر بازنمونهگیری بوتاسترپ نمایانگر یک مجموعهداده جایگزین است که اگر نمونهگیری تحت همان شرایط تکرار میشد میتوانست مشاهده گردد. بنابراین، مقادیر پشتیبانی بوتاسترپ معیارهایی از پایداری در نمونههای تکراریاند و با مفهوم فرکانسی احتمال (بهعنوان بسامد بلندمدت) سازگارند.
این امر در تضاد با رویکرد بیزی (Bayesian) است که در آن مقادیر پشتیبانی – یعنی احتمالات پسین (Posterior Probabilities) – بازتاب درجه باور هستند، با توجه به توزیع پیشین و دادههای مشاهدهشده.
درک این تفاوت فلسفی کمک میکند بفهمیم چرا مقادیر بوتاسترپ نمیتوانند بهطور مستقیم معادل احتمالات پسین باشند، هرچند هر دو برای سنجش پشتیبانی درخت بهکار میروند. هر کدام نماینده نوع متفاوتی از عدم قطعیت هستند:
-
یکی ریشه در فراوانی بازنمونهگیریها دارد،
-
دیگری در احتمال شرطی.
بخش چهارم: بوتاسترپ در عمل
جریان کلی اجرای یک تحلیل بوتاسترپ
اجرای یک تحلیل بوتاسترپ در فیلوژنی (phylogenetics) معمولاً از یک جریان کاری استاندارد پیروی میکند، اگرچه بسته به نوع داده و نرمافزار مورد استفاده، جزئیات میتوانند متفاوت باشند. فرآیند با یک داده اولیه (مانند همترازی یا alignment توالیهای DNA یا پروتئین) آغاز میشود که بهعنوان مبنای بازنمونهگیری (resampling) عمل میکند.
در بوتاسترپ غیرپارامتریک کلاسیک، همترازی ستون به ستون و با جایگزینی (sampling with replacement) بازنمونهگیری میشود تا یک شبههمترازی (pseudo-alignment) با همان طول ایجاد شود. این فرآیند باعث میشود تعداد کل کاراکترها ثابت بماند اما تغییرپذیری وارد داده شود، چون برخی کاراکترها چند بار تکرار میشوند و برخی اصلاً ظاهر نمیشوند.
سپس از این شبههمترازیها یک درخت فیلوژنتیک با همان روش استنباطی که برای داده اصلی استفاده شده (مثلاً بیشینه صرفهجویی یا Maximum Parsimony، بیشینه درستنمایی یا Maximum Likelihood، یا روشهای فاصلهای Distance-based) بازسازی میشود.
این کار بارها تکرار میشود (معمولاً هزاران بار) تا یک مجموعه بزرگ از درختهای بوتاسترپ ایجاد گردد.
ایجاد شبههمترازیها
ایجاد شبههمترازیها (pseudo-alignments) اساس تحلیل بوتاسترپ غیرپارامتریک است. با بازنمونهگیری کاراکترها همراه با جایگزینی، بوتاسترپ فرآیند نمونهگیریهای تکراری از کل جمعیت تاریخچههای تکاملی ممکن را شبیهسازی میکند.
هر شبههمترازی با دیگری متفاوت است و این تفاوتها بازتاب تنوع تصادفی واقعی در دادهها هستند. برای نمونه، در یک همترازی DNA با ۱۰۰۰ سایت، یک شبهتکرار بوتاسترپ نیز شامل ۱۰۰۰ سایت خواهد بود، اما حدود یکسوم سایتها تکراری خواهند بود و برخی سایتهای اصلی اصلاً ظاهر نخواهند شد.
این شبههمترازیها بهعنوان مجموعههای داده جایگزین ممکن عمل میکنند و تحلیل آنها به پژوهشگران اجازه میدهد بفهمند کدام روابط فیلوژنتیک بهطور مداوم حمایت میشوند و کدام حساس به ترکیب خاص کاراکترها هستند.
استنباط درخت برای هر تکرار
پس از ایجاد هر شبههمترازی، باید آن را با یک روش استنباط درخت تحلیل کرد. انتخاب روش استنباطی بسیار مهم است چون مقادیر پشتیبانی بوتاسترپ نهتنها بازتاب دادهها بلکه بازتاب ویژگیهای الگوریتم استنباط هم هستند.
-
اگر پارسیمنی (Parsimony) استفاده شود، درختهای بوتاسترپ نمایانگر سادهترین راهحلها برای دادههای شبهتکرار خواهند بود.
-
اگر بیشینه درستنمایی (Maximum Likelihood) انتخاب شود، هر تکرار یک درخت بهینه بر اساس مدل جایگزینی مشخص ارائه میدهد.
-
بهطور عملی، بیشینه درستنمایی رایجترین روش در تحلیل بوتاسترپ است چون از نظر آماری دقیق و مقاوم است، اگرچه روشهای فاصلهای و پارسیمنی همچنان در برخی زمینهها کاربرد دارند.
در هر حال، تکرارهای متوالی بازسازی درختها یک توزیع از توپولوژیها تولید میکند که تنوع دادهها را بازتاب میدهد.
درختهای اجماعی و مقادیر پشتیبانی
پس از تکمیل صدها یا هزاران تکرار (مثلاً ۵۰۰، ۱۰۰۰ یا حتی ۱۰,۰۰۰)، مرحله بعدی خلاصهسازی نتایج در یک درخت اجماعی (Consensus Tree) است.
-
رایجترین روش، اجماع اکثریت (Majority-rule consensus) است که در آن یک کلاد (Clade) فقط در صورتی در درخت اجماعی وارد میشود که در بیش از ۵۰٪ از درختهای بوتاسترپ ظاهر شده باشد.
-
هر کلاد در درخت اجماعی با یک مقدار پشتیبانی بوتاسترپ (Bootstrap Support Value) مشخص میشود که نشاندهنده درصد تکرارهایی است که آن کلاد در آنها ظاهر شده است.
برای نمونه، اگر یک کلاد شامل گونههای A، B و C در ۸۵۰ مورد از ۱۰۰۰ تکرار ظاهر شود، مقدار پشتیبانی آن ۸۵٪ خواهد بود. این مقادیر روی درخت فیلوژنتیک نمایش داده میشوند و نشان میدهند کدام شاخهها قوی یا ضعیف حمایت میشوند.
تفسیر مقادیر بوتاسترپ
مقادیر بوتاسترپ معمولاً بهعنوان معیار پایداری کلادها تحت بازنمونهگیری تفسیر میشوند. در عمل:
-
مقادیر بالاتر از ۷۰٪ معمولاً نشاندهنده حمایت متوسط هستند.
-
مقادیر بالاتر از ۹۰ یا ۹۵٪ نشاندهنده حمایت قوی هستند.
اما این آستانهها مطلق نیستند و نباید با احتمال واقعی درستی یک شاخه اشتباه گرفته شوند.
-
یک شاخه با ۹۵٪ بوتاسترپ لزوماً درست نیست؛ بلکه فقط نشان میدهد دادهها در بیشتر تکرارها آن را بازتولید کردهاند.
-
مقادیر پایین هم لزوماً به معنای نادرستی کلاد نیستند؛ ممکن است فقط اطلاعات ناکافی یا سیگنالهای متناقض در دادهها وجود داشته باشد.
پس تفسیر مقادیر بوتاسترپ باید همراه با توجه به اندازه داده، مدلهای تکاملی و سوگیریهای احتمالی انجام شود.
نیازهای محاسباتی
تحلیل بوتاسترپ میتواند از نظر محاسباتی سنگین باشد چون باید برای هر شبهداده یک درخت بازسازی شود.
-
برای مجموعههای کوچک و روشهای ساده مثل پارسیمنی مشکلی نیست.
-
اما برای دادههای بزرگ مولکولی با روشهای درستنمایی، بار محاسباتی میتواند بسیار زیاد باشد، بهویژه اگر هزاران تکرار لازم باشد.
با این حال، پیشرفتهای قدرت محاسباتی و الگوریتمی مثل Rapid Bootstrap در RAxML یا Ultrafast Bootstrap در IQ-TREE این مشکل را کاهش دادهاند. این روشها نتایج بوتاسترپ را با دقت بالا و زمان بسیار کمتر ارائه میدهند و امکان تحلیل مجموعه دادههای عظیم ژنومی با صدها یا هزاران تاکسون را فراهم میکنند.
ملاحظات عملی در آمادهسازی دادهها
موفقیت تحلیل بوتاسترپ به شدت وابسته به کیفیت دادههاست. توالیهای بد همتراز شده، کاراکترهای مبهم، یا دادههای مفقود زیاد میتوانند دقت مقادیر بوتاسترپ را کاهش دهند.
-
در دادههای مولکولی: باید همترازی درست انجام شود، نواحی بد همتراز حذف شوند و مدلهای جایگزینی مناسب انتخاب شوند.
-
در دادههای ریختشناسی (Morphological): باید کدگذاری کاراکترها با دقت انجام شود و ذهنی بودن در امتیازدهی صفات به حداقل برسد.
بوتاسترپ قادر به اصلاح کیفیت پایین دادهها نیست؛ تنها نشان میدهد دادههای موجود تا چه حد یک توپولوژی را بهطور مداوم پشتیبانی میکنند.
گزارش و تجسم نتایج بوتاسترپ
در مقالات فیلوژنتیک، مقادیر بوتاسترپ معمولاً بهصورت عدد روی شاخههای درخت نمایش داده میشوند.
-
برخی پژوهشگران مقادیر زیر ۵۰٪ را حذف میکنند چون نشاندهنده گروهبندیهای بیثبات هستند.
-
برخی دیگر برای شفافیت، همه مقادیر را نشان میدهند.
-
درختهای بزرگ با تاکسونهای زیاد ممکن است با نمایش گرافیکی مثل ضخامت شاخه متناسب با مقدار پشتیبانی، بهتر تجسم شوند.
بهطور کلی، گزارش واضح مقادیر بوتاسترپ یک رویه استاندارد در فیلوژنتیک مدرن است.
ادغام با سایر معیارهای پشتیبانی
اگرچه بوتاسترپ یکی از رایجترین معیارهاست، امروزه بسیاری از پژوهشگران آن را با روشهای دیگر تکمیل میکنند، مانند:
-
احتمالهای پسین بیزی (Bayesian Posterior Probabilities)
-
آزمونهای تقریبی نسبت درستنمایی (Approximate Likelihood Ratio Tests)
در عمل، معمول است که مقادیر بوتاسترپ همراه با مقادیر بیزی گزارش شوند.
-
وقتی هر دو روش همراستا باشند → اعتماد به نتیجه بیشتر میشود.
-
وقتی اختلاف داشته باشند → این اختلاف خود میتواند اطلاعات مهمی درباره ویژگیهای داده یا فرضیات مدلها بدهد.
بنابراین، بوتاسترپ معمولاً نقطه شروع برای ارزیابی اطمینان فیلوژنتیک است، اما در کنار دیگر ابزارها قدرت واقعی خود را نشان میدهد.
بخش پنجم: کاربردهای بوتاسترپ در فیلوژنی
فیلوژنی مولکولی (Molecular Phylogenetics)
بوتاسترپ بیشترین کاربرد خود را در فیلوژنی مولکولی پیدا کرده است، جایی که دادههای توالی DNA، RNA و پروتئین ستون فقرات استنباطهای تکاملی را تشکیل میدهند. در این زمینه، تحلیل بوتاسترپ روشی برای سنجش این است که روابط استنباطشده تا چه اندازه نسبت به نمونهگیری از سایتها در یک همترازی توالی مقاوم هستند.
برای نمونه، در مطالعات مربوط به تکامل مهرهداران، همترازیهای بزرگ ژنومهای میتوکندری یا ژنهای هستهای تحلیل میشوند تا فیلوژنیهای سطح گونه بازسازی شوند. با بهکارگیری بوتاسترپ، پژوهشگران میتوانند تعیین کنند کدام کلادها بهطور پیوسته در دادههای بازنمونهگیریشده بازیابی میشوند و کدام تنها بهطور ضعیفی حمایت میشوند.
این اطلاعات در زمان ارزیابی فرضیههای رقیب ــ مانند جایگاه لاکپشتها در میان خزندگان یا روابط میان شاخههای اصلی پستانداران ــ حیاتی هستند. استفاده گسترده از بوتاسترپ در فیلوژنی مولکولی همچنین به شکلگیری استانداردهای غیررسمی منجر شده است:
-
مقادیر بالای ۷۰٪ معمولاً بهعنوان حمایت متوسط تعبیر میشوند.
-
مقادیر بالای ۹۰ یا ۹۵٪ بهعنوان شواهد قوی برای یک کلاد در نظر گرفته میشوند.
این معیارها مطلق نیستند، اما به زبان مشترک (lingua franca) در این حوزه تبدیل شدهاند و تفسیر درختهای مولکولی را هدایت میکنند.
فیلوژنی ریختشناسی (Morphological Phylogenetics)
اگرچه بوتاسترپ بیش از همه با دادههای مولکولی مرتبط است، اما در فیلوژنی ریختشناسی نیز بهکار گرفته شده است. در این زمینه، کاراکترها صفات ریختشناسی هستند، مانند ساختارهای استخوانی، دستگاههای اندامی یا ویژگیهای تکوینی که بهعنوان متغیرهای گسسته کدگذاری میشوند.
با بازنمونهگیری کاراکترها همراه با جایگزینی، تحلیل بوتاسترپ به پژوهشگران اجازه میدهد بررسی کنند که چه گروهبندیهایی در نمونهگیریهای تکراری پایدار باقی میمانند. این موضوع بهویژه در دیرینهشناسی (Paleontology) اهمیت دارد، جایی که دادههای ریختشناسی اغلب تنها منبع اطلاعات فیلوژنتیک هستند.
-
بهعنوان مثال، در مطالعات مربوط به فسیلهای هومینینها (hominins) از بوتاسترپ برای سنجش استحکام روابط پیشنهادی میان نیاکان اولیه انسان استفاده شده است.
-
همچنین در تحلیل خزندگان منقرضشده و نخستین چهاراندامداران (early tetrapods)، بوتاسترپ به کار رفته تا ثبات فرضیههای رقیب درباره جایگاه تکاملی آنها بررسی شود.
اگرچه کاراکترهای ریختشناسی معمولاً کمشمارتر از دادههای مولکولی هستند، بوتاسترپ همچنان در این حوزه ابزاری ارزشمند است که نوعی سختگیری آماری را حتی در شرایط دادههای محدود فراهم میکند.
فیلوژنمیک و مجموعهدادههای بزرگ (Phylogenomics and Large-Scale Datasets)
ظهور فیلوژنمیک (Phylogenomics) ــ یعنی تحلیل فیلوژنتیک مبتنی بر دادههای در مقیاس ژنوم ــ فرصتها و چالشهای تازهای برای بوتاسترپ ایجاد کرده است. مطالعات مدرن اغلب صدها یا هزاران ژن را شامل میشوند و همترازیهایی با میلیونها کاراکتر تولید میکنند.
در چنین مواردی، بوتاسترپ روشی فراهم میکند تا بررسی شود این مجموعه دادههای عظیم تا چه اندازه از روابط خاصی مانند ترتیب انشعاب شاخههای عمیق متازوآ (Metazoa) یا روابط میان گیاهان گلدار حمایت میکنند.
-
پیشرفتهای محاسباتی این امکان را ایجاد کردهاند که روش بوتاسترپ روی این دادههای بزرگ اعمال شود بدون آنکه هزینه محاسباتی غیرقابلتحملی داشته باشد.
-
الگوریتمهای سریع و فوقسریع بوتاسترپ (Fast و Ultrafast Bootstrap) که در نرمافزارهایی مانند RAxML و IQ-TREE پیادهسازی شدهاند، امکان تحلیل دادههای فیلوژنمیک با صدها تاکسون و هزاران لوکوس (loci) را فراهم کردهاند.
مقادیر پشتیبانی بهدستآمده کمک میکنند تا پژوهشگران کلادهایی که بهطور بیچونوچرا توسط دادههای ژنومی حمایت میشوند را از آنهایی که با وجود دادههای فراوان همچنان نامطمئناند، متمایز کنند. این کاربرد نشان میدهد که بوتاسترپ توانسته با مقیاس روزافزون زیستشناسی تکاملی مدرن همگام شود.
اپیدمیولوژی و تکامل پاتوژنها (Epidemiology and Pathogen Evolution)
یکی از تأثیرگذارترین کاربردهای بوتاسترپ در دهههای اخیر در اپیدمیولوژی بوده است، بهویژه در مطالعه پاتوژنهای در حال تکامل سریع مانند ویروسها و باکتریها.
در این زمینه، تحلیل فیلوژنتیک برای ردیابی منشأها، مسیرهای انتقال، و پویایی تکاملی بیماریهای عفونی به کار میرود. تحلیل بوتاسترپ چارچوبی آماری برای سنجش اعتماد به مسیرهای انتقال استنباطشده و روابط تکاملی فراهم میکند.
-
برای نمونه، در طی شیوع HIV، آنفلوآنزا، و اخیراً SARS-CoV-2، مقادیر بوتاسترپ برای ارزیابی استحکام کلادهایی که نمایانگر تبارهای ویروسی بودند، استفاده شدند.
-
این مقادیر میتوانند در تصمیمگیریهای بهداشت عمومی نقش داشته باشند، چون نشان میدهند کدام الگوهای تکاملی به اندازه کافی قابل اعتماد هستند تا مداخلات بر اساس آنها صورت گیرد.
-
افزون بر این، در فیلوژنیهای باکتریایی از بوتاسترپ برای ردیابی گسترش ژنهای مقاومت آنتیبیوتیکی و در پاتوژنهای قارچی برای درک ظهور سویههای بیماریزای جدید استفاده شده است.
به این ترتیب، بوتاسترپ تضمین میکند که استنباطهای اپیدمیولوژیک بر شواهد آماری محکم استوار باشند.
زیستشناسی حفاظت (Conservation Biology)
در زیستشناسی حفاظت (Conservation Biology)، تحلیل بوتاسترپ نقش حیاتی در شناسایی و اولویتبندی تبارهای تکاملی برای حفاظت ایفا میکند.
-
درختهای فیلوژنتیک بهطور فزایندهای برای اندازهگیری تنوع زیستی، سنجش تمایز تکاملی، و شناسایی گونههای پنهان (Cryptic Species) به کار میروند.
-
مقادیر پشتیبانی بوتاسترپ تضمین میکنند که تبارهایی که مبنای تصمیمهای حفاظتی هستند، با اطمینان کافی استنباط شدهاند.
برای نمونه:
-
در مطالعات مربوط به دوزیستان، خزندگان و گیاهان، بوتاسترپ برای ارزیابی استحکام مرزهای گونهای و شناسایی تبارهایی که ممکن است بهعنوان تاکسونهای جداگانه شناخته شوند، استفاده شده است.
-
در مطالعات پستانداران در معرض خطر، بوتاسترپ کمک کرده تا روشن شود آیا جمعیتها باید بهعنوان واحدهای حفاظتی جداگانه در نظر گرفته شوند یا خیر.
این کاربردها نشان میدهند که تحلیل بوتاسترپ فراتر از زیستشناسی تکاملی نظری، در تصمیمگیریهای واقعی حفاظت تنوع زیستی نقش عملی دارد.
کاربردهای قضایی و حقوقی (Forensic and Legal Applications)
یکی از کاربردهای نوظهور بوتاسترپ در علم پزشکی قانونی (Forensic Science) است، جایی که روشهای فیلوژنتیک گاهی برای بررسی پروندههای جنایی شامل انتقال بیماریهای عفونی به کار میروند.
در این زمینه، مقادیر بوتاسترپ شاخصی حیاتی برای سنجش قابلیت اعتماد روابط استنباطشده میان توالیهای ویروسی از افراد مختلف هستند.
-
برای مثال، در پروندههایی که شامل انتقال احتمالی HIV بودند، تحلیل فیلوژنتیک همراه با پشتیبانی بوتاسترپ برای بررسی نزدیک بودن سویههای ویروسی فرد مظنون و قربانی بهکار رفته است.
-
از آنجا که تصمیمهای حقوقی ممکن است بر اساس استحکام چنین استنباطهایی اتخاذ شوند، بوتاسترپ بهعنوان ابزاری ضروری برای جلوگیری از تفسیر بیشازحد روابط ضعیف حمایتشده عمل میکند.
اگرچه این کاربردها نادر و بحثبرانگیز هستند، اما نشان میدهند که تحلیل بوتاسترپ تا چه اندازه وارد حوزههای گوناگون علم و جامعه شده است.
آموزش و ارتباطات (Education and Communication)
بوتاسترپ همچنین نقش مهمی در آموزش و ارتباطات فیلوژنتیک ایفا میکند. چون مقادیر بوتاسترپ بهصورت درصد بیان میشوند، درکی شهودی و ساده از میزان عدم قطعیت در درختهای فیلوژنتیک ارائه میدهند.
-
در کلاسهای درس، نتایج بوتاسترپ اغلب برای نشان دادن این استفاده میشوند که چگونه نمونهگیریهای تکراری میتوانند بر استنباطهای تکاملی تأثیر بگذارند و به دانشجویان مدخلی ساده به تفکر آماری ارائه کنند.
-
در ارتباطات عمومی، درختهایی که با مقادیر بوتاسترپ حاشیهنویسی شدهاند به روزنامهنگاران، سیاستگذاران و عموم مردم کمک میکنند بفهمند که روابط تکاملی قطعیت مطلق ندارند، بلکه فرضیههایی با درجات مختلف حمایت هستند.
از این منظر، بوتاسترپ نهتنها یک ابزار علمی بلکه پل ارتباطی میان پژوهش فنی و مخاطبان گستردهتر است.
جمعبندی کاربردها (Summary of Applications)
این کاربردها در مجموع نشان میدهند که بوتاسترپ تحلیلی همهکاره و با اهمیت ماندگار در فیلوژنی است.
-
از کاربرد آن در مجموعههای داده کلاسیک ریختشناسی تا نقش مرکزیاش در فیلوژنمیک در مقیاس بزرگ، بوتاسترپ توانسته خود را با دادهها و زمینههای پژوهشی متنوع تطبیق دهد.
-
تأثیر آن فراتر از زیستشناسی تکاملی به حوزههای کاربردی چون اپیدمیولوژی، حفاظت و حتی حقوق گسترش یافته است.
-
در هر یک از این حوزهها، بوتاسترپ زبان آماری مشترکی برای بیان اعتماد به فرضیههای فیلوژنتیک فراهم کرده است و تضمین کرده که استنباطها شفاف و مستحکم باشند.
بنابراین، این روش به جزئی جداییناپذیر از عمل فیلوژنتیک مدرن تبدیل شده و بر نحوه مطالعه، تفسیر و بهکارگیری روابط تکاملی اثر گذاشته است.
بخش ششم: نقاط قوت تحلیل بوتاسترپ (Strengths of Bootstrap Analysis)
سادگی مفهومی و جذابیت شهودی (Conceptual Simplicity and Intuitive Appeal)
یکی از مهمترین نقاط قوت تحلیل بوتاسترپ در فیلوژنی، سادگی مفهومی آن است. در اساس، این روش بر یک فرایند بازنمونهگیری ساده تکیه دارد که بهآسانی قابل درک و انتقال است.
در این روش، با نمونهگیری همراه با جایگزینی از دادهها، مجموعهدادههای مصنوعی (pseudo-datasets) تولید میشوند و سپس از این مجموعهها درختهای فیلوژنتیک بازسازی میشوند. خروجی این تحلیل مقادیر حمایتی است که به شکل درصد بیان میشوند.
این نمایش شهودی باعث میشود که روش بوتاسترپ نهتنها برای متخصصان زیستشناسی تکاملی، بلکه برای دانشجویان، سیاستگذاران و پژوهشگران میانرشتهای هم قابل دسترسی باشد. برخلاف برخی معیارهای آماری که نیازمند آشنایی عمیق با نظریه احتمال یا توابع درستنمایی (Likelihood Functions) هستند، مقادیر بوتاسترپ بهراحتی قابل تفسیرند:
-
یک کلاد که در ۹۵٪ از درختهای بازنمونهگیریشده ظاهر میشود، بهطور واضح قابل اعتمادتر است از کلادی که فقط در ۴۰٪ دیده میشود.
این شفافیت در تفسیر، بوتاسترپ را به یک استاندارد پایدار در پژوهشهای فیلوژنتیک تبدیل کرده است.
کاربردپذیری گسترده در انواع دادهها (Broad Applicability Across Data Types)
دیگر نقطه قوت چشمگیر بوتاسترپ، چندکاره بودن و انعطافپذیری آن است. این روش به هیچ نوع خاصی از دادههای کاراکتری یا مدل تکاملی محدود نمیشود.
چه مجموعهداده شامل توالیهای DNA باشد، چه همترازی پروتئینها یا حتی صفات ریختشناسی، بوتاسترپ تقریباً به همان روش، یعنی بازنمونهگیری واحدهای مشاهدهای اصلی، قابل اجراست.
این عمومیت سبب شده بوتاسترپ به یک چارچوب یکپارچه در میان زیرشاخههای مختلف فیلوژنی تبدیل شود:
-
از مطالعات دیرینهشناسی روی تاکسونهای فسیلی
-
تا پروژههای مدرن فیلوژنمیک که شامل هزاران ژن میشوند.
این ویژگی تضمین میکند که پژوهشگرانی با دادههای بسیار متفاوت، همچنان بتوانند به یک استاندارد مشترک برای ارزیابی اعتماد به درختها تکیه کنند و این امر، ارتباطات میانرشتهای و مقایسهها را آسانتر میسازد.
استقلال از فرضیات پارامتریک قوی (Independence from Strong Parametric Assumptions)
تحلیل بوتاسترپ همچنین ارزشمند است زیرا به فرضیات پارامتریک قوی درباره توزیع زیرین کاراکترها وابسته نیست.
در حالی که آزمونهای آماری سنتی اغلب نیازمند فرضهایی مانند:
-
نرمال بودن توزیع (Normality)
-
همگنی واریانسها (Homoscedasticity)
-
یا استقلال دادهها هستند،
این فرضها همیشه در دادههای تکاملی واقعی صدق نمیکنند.
بوتاسترپ بسیاری از این محدودیتها را دور میزند، زیرا به جای تکیه بر توزیعهای نظری، خود دادهها را مبنای بازنمونهگیری قرار میدهد.
این ماهیت غیرپارامتریک (Non-parametric)، بوتاسترپ را بهویژه در شرایطی که فرایندهای تکاملی مولد دادهها پیچیده، ناشناخته یا سخت برای مدلسازی صریح هستند، مقاوم و کاربردی میسازد.
به همین دلیل، بوتاسترپ یک راهکار عملگرایانه برای سنجش اعتماد فراهم میکند، حتی در جایی که رویکردهای پارامتریک نامناسب یا غیرقابلاعتماد باشند.
پذیرش گسترده و استانداردسازی (Widespread Acceptance and Standardization)
از زمان معرفیاش، تحلیل بوتاسترپ بهطور عمیق در رویههای رایج فیلوژنتیک جا افتاده است.
-
بهطور گسترده بهعنوان یک معیار استاندارد برای حمایت شاخهها شناخته میشود.
-
بسیاری از مجلات علمی و داوران مقالات انتظار دارند که مقادیر بوتاسترپ همراه با درختهای منتشرشده گزارش شوند.
این پذیرش گسترده نشاندهنده اعتماد به این روش و نقش تاریخی آن در شکلگیری این حوزه است.
به دلیل استفاده و گزارشدهی گسترده از بوتاسترپ، تفسیر آن نیز استاندارد شده است:
-
مقادیر بالای ۷۰٪ معمولاً نشانگر حمایت متوسط هستند.
-
مقادیر بالای ۹۰ یا ۹۵٪ نشاندهنده حمایت قویاند.
این اجماع علمی برای پژوهشگران یک چارچوب مشترک تفسیری فراهم میکند و مقایسه میان مطالعات و مجموعهدادههای مختلف را ممکن میسازد.
در نتیجه، بوتاسترپ نهتنها به تحلیلهای فردی کمک میکند، بلکه به انباشت دانش در کل این رشته نیز یاری میرساند.
سازگاری با ابزارهای محاسباتی مدرن (Compatibility with Modern Computational Tools)
توسعه الگوریتمها و نرمافزارهای کارآمد، قدرت بوتاسترپ را بیشازپیش افزایش داده است.
-
برنامههایی مانند PAUP*، MEGA، RAxML، PhyML و IQ-TREE، روش بوتاسترپ را بهعنوان ویژگی استاندارد در خود جای دادهاند.
-
این موضوع باعث شده پژوهشگران بتوانند تحلیلها را با حداقل تلاش اضافه انجام دهند.
پیشرفتهای محاسباتی مانند موازیسازی (Parallelization) و الگوریتمهای بوتاسترپ فوقسریع (Ultrafast Bootstrap) نیز امکان اعمال این روش بر مجموعهدادههای بسیار بزرگ را فراهم کردهاند؛ مجموعههایی که فقط یک دهه پیش از نظر محاسباتی غیرممکن بودند.
این سازگاری با محیطهای نرمافزاری مدرن تضمین میکند که بوتاسترپ همچنان هم عملی و هم قابل مقیاسپذیری باقی بماند و بتواند با رشد نمایی دادههای مولکولی و ژنومی در پژوهشهای تکاملی همگام شود.