مدل سازی پراکنش گونه
بخش ۱: مقدمه و پیشینه تاریخی
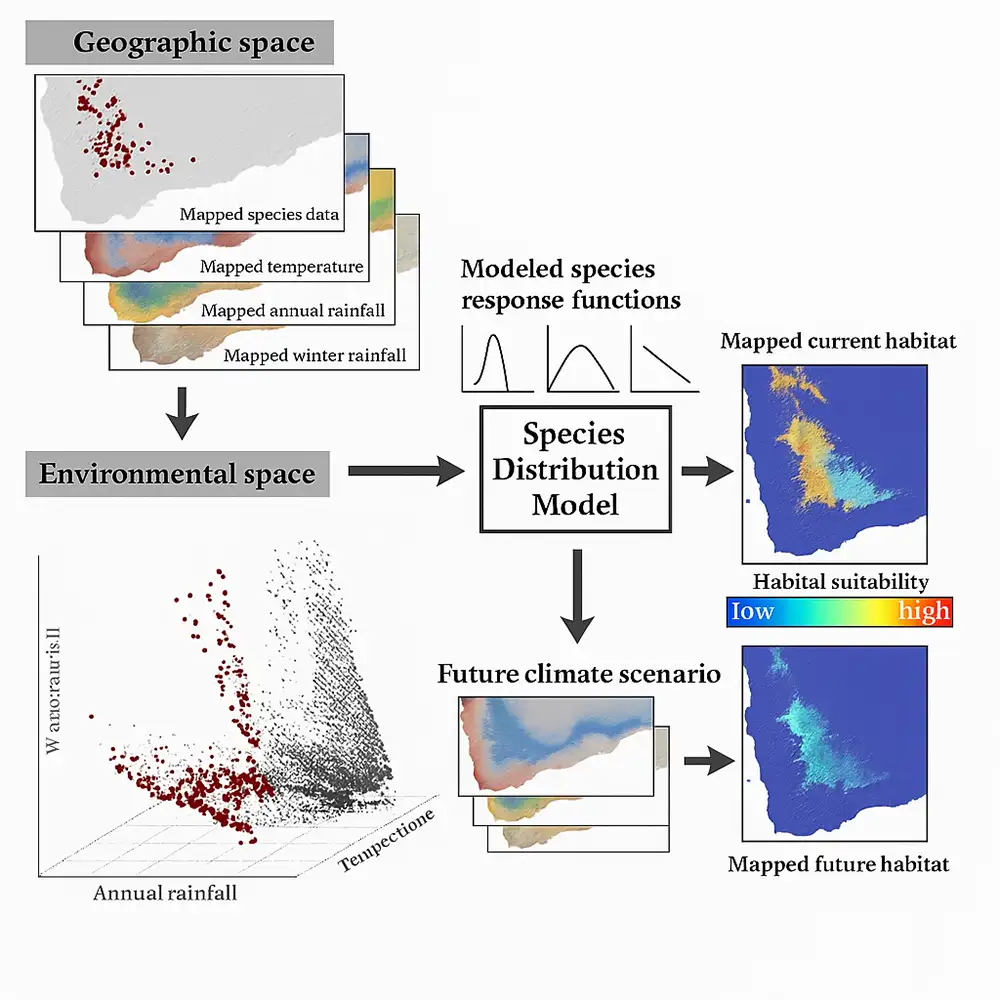
مدلسازی پراکندگی گونهها (Species Distribution Modeling – SDM)، که به آن مدلسازی زیستگاه بومشناختی (Ecological Niche Modeling – ENM) نیز گفته میشود، یکی از ابزارهای پایهای در اکولوژی مدرن، جغرافیای زیستی و علوم حفاظت از محیط زیست است. از SDMها برای پیشبینی پراکندگی جغرافیایی گونهها بر اساس عوامل محیطی، دادههای حضور گونهها و، بهطور فزاینده، دادههای مکانیکی و فیزیولوژیکی استفاده میشود. با ارتباط آماری دادههای حضور یا فراوانی گونهها با پیشبینیکنندههای محیطی، SDMها نقشههایی از مناسب بودن زیستگاه تولید میکنند، محدودههای احتمالی پراکندگی را مشخص میکنند و تغییرات پراکندگی تحت اختلالات محیطی مانند تغییرات اقلیمی، تخریب زیستگاه یا ورود گونههای مهاجم را پیشبینی میکنند.
ریشههای مفهومی SDM در نظریه زیستگاه (Ecological Niche Theory) است که توسط Hutchinson (1957) معرفی شد. این نظریه زیستگاه را بهعنوان یک ابرحجم n-بعدی از شرایط محیطی تعریف میکند که گونه قادر به بقا و تولیدمثل در آن است. هاتچینسون بین زیستگاه بنیادی (Fundamental Niche)، که محدوده کامل شرایطی است که یک گونه بدون حضور رقبا یا شکارچیان میتواند اشغال کند، و زیستگاه واقعی (Realized Niche)، که بخشی از زیستگاه است که واقعاً گونه اشغال کرده به دلیل تعاملات زیستی و محدودیتهای پراکنش، تفاوت قائل شد. این تمایز برای تفسیر پیشبینیهای SDM حیاتی است: اکثر SDMها زیستگاه واقعی را بر اساس دادههای مشاهدهشده تخمین میزنند، اما پیشبینیها اغلب فرض میکنند گونهها در تعادل با محیط خود هستند، که این فرض ممکن است در مناظر در حال تغییر سریع صدق نکند.
۱.۱ پیشینه تاریخی
توسعه مدلسازی پراکندگی گونهها تحت تأثیر پیشرفتهای نظریه اکولوژی، آمار و فناوریهای ژئومکانیکی (GIS) شکل گرفته است. مطالعات اولیه زیستجغرافیایی عمدتاً بر مشاهدات توصیفی و ترسیم پراکندگی گونهها بر اساس دستهبندیهای زیستگاهی متکی بودند. با رشد اکولوژی کمی در میانه قرن بیستم، پژوهشگران شروع به استفاده از تکنیکهای رگرسیون آماری برای ارتباط دادن حضور یا عدم حضور گونهها با گرادیانهای محیطی کردند. رگرسیون لجستیک (Logistic Regression) به ابزار پرکاربردی تبدیل شد، زیرا امکان تخمین احتمال حضور گونهها به عنوان تابعی از چندین متغیر پیشبینیکننده را فراهم میکرد. بعدها، مدلهای خطی تعمیمیافته (GLM) و مدلهای افزایشی تعمیمیافته (GAM) امکان مدلسازی روابط غیرخطی و پیچیده بین گونه و محیط را فراهم کردند و قدرت پیشبینی را افزایش دادند.
دهه ۱۹۹۰ نقطه عطفی در این حوزه بود، با ظهور سیستمهای اطلاعات جغرافیایی (GIS) و دسترسی فزاینده به دادههای گسترده حضور گونهها، مانند دادههای موزهها، گیاهشناسی و پروژههای علمی مردمی. این پیشرفتها اجازه داد لایههای محیطی با وضوح بالا با دادههای گونهها ادغام شوند و مدلسازی مکانی با دقت بالا در مقیاسهای منطقهای و جهانی انجام شود. در همین زمان، روشهای مدلسازی فقط با دادههای حضور (Presence-only Modeling) به ویژه مدلسازی بیشینه آنتروپی (MaxEnt) محبوب شدند. MaxEnt با حداکثر کردن آنتروپی تحت محدودیتهای محیطی در سایتهای حضور گونهها، توزیع احتمالی گونهها را تخمین میزند. این روش به دلیل عملکرد خوب با دادههای ناقص عدم حضور، که در مطالعات اکولوژیکی رایج است، به طور گسترده پذیرفته شد.
ظهور مدلسازی تجمیعی (Ensemble Modeling) در دهه ۲۰۰۰، پیشرفت بیشتری در این حوزه ایجاد کرد. روشهای تجمیعی پیشبینیهای چندین الگوریتم مختلف مانند GLM، GAM، Random Forest و MaxEnt را ترکیب میکنند تا پیشبینیهای قابل اعتمادتر و دقیقتر تولید شود. این روشها عدم قطعیت ذاتی هر الگوریتم منفرد را در نظر میگیرند و دقت پیشبینی را بهویژه هنگام پیشبینی پراکندگی گونهها در شرایط محیطی جدید، مانند سناریوهای اقلیمی آینده، افزایش میدهند. از آن زمان، SDMها در کاربردهای عملی زیادی استفاده شدهاند، از حفاظت از تنوع زیستی و مدیریت گونههای مهاجم گرفته تا ارزیابی اثرات تغییرات اقلیمی و اپیدمیولوژی.
۱.۲ مرور مفهومی
از نظر مفهومی، SDMها بر این اساس شکل گرفتهاند که وقوع گونهها تصادفی نیست و نشاندهنده ترجیحات و محدودیتهای محیطی پایهای است. فرآیند مدلسازی معمولاً شامل سه مؤلفه اصلی است: دادههای حضور گونه، متغیرهای پیشبینیکننده محیطی و الگوریتم مدلسازی که این دو را به هم مرتبط میکند. دادههای حضور گونهها میتوانند فقط حضور (Presence-only)، حضور-عدم حضور (Presence-Absence) یا کمتر رایج دادههای فراوانی (Abundance Data) باشند. پیشبینیکنندههای محیطی شامل متغیرهای اقلیمی (دمای هوا، بارش)، ویژگیهای توپوگرافی (ارتفاع، شیب، جهتگیری)، عوامل خاکی و ادمیک (Soil/Edaphic)، پوشش زمین و تأثیرات انسانی هستند. این پیشبینیکنندهها فضای محیطی را که گونه در آن وجود دارد تعریف میکنند.
گردش کار مدلسازی با پیشپردازش دادهها آغاز میشود که شامل پاکسازی دادهها، فیلتر مکانی برای کاهش سوگیری نمونهبرداری و انتخاب پیشبینیکنندههای زیستمحیطی مرتبط است. پس از پیشپردازش، دادهها برای کالیبراسیون مدل با استفاده از الگوریتمهای آماری یا یادگیری ماشین استفاده میشوند. مدل حاصل احتمال حضور یا مناسب بودن زیستگاه در سراسر چشمانداز را تخمین میزند. سپس، معیارهای ارزیابی و اعتبارسنجی مانند سطح زیر منحنی (AUC)، شاخص مهارت واقعی (TSS) یا آماره کپا (Kappa) برای سنجش عملکرد پیشبینی به کار گرفته میشوند. در نهایت، مدل میتواند برای سناریوهای مکانی یا زمانی جایگزین، مانند شرایط اقلیمی آینده یا سناریوهای بازسازی زیستگاه، پروژه شود.
۱.۳ کاربردها و اهمیت
SDMها در پژوهشهای اکولوژیکی و حفاظت محیط زیست کاربردهای گستردهای دارند. در برنامهریزی حفاظت محیط زیست، آنها به شناسایی زیستگاههای حیاتی، اولویتبندی مناطق برای حفاظت و طراحی شبکهای از ذخیرهگاهها کمک میکنند. در زمینه تغییرات اقلیمی، SDMها تغییرات احتمالی محدوده گونهها و شناسایی پناهگاههای اقلیمی (Climate Refugia) که ممکن است اولویتهای حفاظتی آینده باشند را پیشبینی میکنند. مدیریت گونههای مهاجم نیز از SDMها بهره میبرد، زیرا مدلها گسترش احتمالی گونهها را پیشبینی کرده و راهبردهای شناسایی زودهنگام و کاهش اثرات را اطلاعرسانی میکنند. فراتر از حفاظت، SDMها در اپیدمیولوژی برای نقشهبرداری از پراکندگی ناقلها یا میزبانان بیماری، در جنگلداری و کشاورزی برای پیشبینی مناسب بودن گونهها، و در پژوهشهای اکولوژیکی برای درک الگوهای زیستجغرافیایی و عوامل مؤثر بر تنوع زیستی به کار میروند.
با وجود کاربردهای گسترده، SDMها با چالشهایی نیز مواجه هستند. از جمله مهمترین مسائل میتوان به سوگیری نمونهبرداری در دادههای حضور گونهها، همخطی (Multicollinearity) بین پیشبینیکنندههای محیطی و فرض تعادل گونه با محیط اشاره کرد. علاوه بر این، SDMها اغلب در برونیابی به شرایط محیطی جدید، مانند تغییرات اقلیمی یا تغییرات زیستگاهی، مشکل دارند. مواجهه با این چالشها نیازمند انتخابهای روششناسی دقیق، ادغام دانش مکانیکی و ارزیابی سختگیرانه عدم قطعیت است.
بخش ۲: نظریهها و اصول اکولوژیکی زیربنای SDM
مدلسازی پراکندگی گونهها (Species Distribution Modeling – SDM) اساساً بر نظریههای اکولوژیکی، بهویژه مفهوم زیستگاه اکولوژیکی (Ecological Niche) تکیه دارد، که چارچوب نظری برای درک عواملی فراهم میکند که پراکندگی گونهها را محدود میکنند. زیستگاه اکولوژیکی مجموعهای از شرایط محیطی و منابعی است که امکان بقا، رشد و تولیدمثل یک گونه را فراهم میکند.
Hutchinson (1957) این مفهوم را به شکل یک ابرحجم n-بعدی (n-dimensional hypervolume) فرمالیزه کرد، که در آن هر بعد نشاندهنده یک متغیر محیطی است که بر بقای گونه تأثیر میگذارد. در این چارچوب، زیستگاه بنیادی (Fundamental Niche) شامل تمامی شرایط غیرزیستی (Abiotic) است که یک گونه میتواند در غیاب تعاملات زیستی در آن وجود داشته باشد، در حالی که زیستگاه واقعی (Realized Niche) زیرمجموعهای از این شرایط است که گونه واقعاً اشغال میکند، پس از در نظر گرفتن رقابت، شکار، بیماری و سایر تعاملات اکولوژیکی. تشخیص تفاوت بین زیستگاه بنیادی و واقعی برای تفسیر پیشبینیهای SDM حیاتی است، زیرا اکثر مدلها بر دادههای مشاهدهشده حضور گونهها متکی هستند که معمولاً زیستگاه واقعی را منعکس میکنند و فرض میکنند که این مشاهدات تمام محدوده تحمل محیطی گونه را ثبت کردهاند.
۲.۱ اصل عوامل محدودکننده (Limiting Factors)
یک اصل مرکزی در SDM، مفهوم عوامل محدودکننده است، که بیان میکند پراکندگی گونهها توسط متغیر محیطی که بیشترین محدودیت را در هر مکان مشخص دارد، کنترل میشود.
مثال: یک گونه گیاهی ممکن است دامنه دمایی وسیعی را تحمل کند اما فقط در خاکهایی با سطوح خاص مواد مغذی زنده بماند. در این حالت، مواد مغذی خاک عامل محدودکنندهای است که پراکندگی گونه را تعیین میکند. به همین ترتیب، شدت دما، الگوهای بارش یا دسترسی فصلی به منابع میتوانند محدودیتهایی برای بقای گونهها ایجاد کنند.
SDMها این اصول را عملیاتی میکنند با شناسایی متغیرهای محیطی که بیشترین همبستگی را با حضور گونهها دارند، که دیدگاههایی درباره فرآیندهای اکولوژیکی کنترلکننده پراکندگی گونهها ارائه میدهد. با کمیسازی این روابط، SDMها به اکولوژیستها اجازه میدهند فراتر از نقشهبرداری توصیفی رفته و به بررسی سازوکارهای زیرین الگوهای فضایی مشاهدهشده بپردازند.
۲.۲ نقش تعاملات زیستی (Biotic Interactions)
تعاملات زیستی نقش حیاتی در شکلدهی زیستگاه واقعی و به تبع آن پراکندگی گونهها دارند.
-
رقابت برای منابع، شکار، روابط همزیستی (Mutualism) و تعاملات تسهیلکننده (Facilitation) میتوانند محدوده حضور گونهها را محدود یا گسترش دهند.
مثال: یک گونه گیاهی ممکن است به لحاظ فیزیولوژیکی قادر به بقا در طیف وسیعی از انواع خاک باشد، اما رقابت با گونههای غالب میتواند پراکندگی آن را به زیرمجموعهای محدود از شرایط محدود کند.
گرچه اکثر SDMها به طور تاریخی بر پیشبینیکنندههای غیرزیستی تمرکز داشتهاند به دلیل دسترسپذیری و ثبات دادهها، اما ادغام تعاملات زیستی بهطور فزایندهای برای بهبود دقت پیشبینیها ضروری شناخته میشود. پیشرفتهای اخیر در مدلسازی مشترک پراکندگی گونهها (Joint Species Distribution Modeling) و SDMهای سطح جامعه (Community-level SDM) به اکولوژیستها اجازه میدهد الگوهای همپوشانی گونهها را بهطور صریح در نظر بگیرند و پیشبینیهای اکولوژیکی واقعیتری تولید کنند.
۲.۳ وابستگی به مقیاس (Scale-dependency)
یکی دیگر از ملاحظات مهم در SDM، وابستگی روابط گونه-محیط به مقیاس است.
-
متغیرهای محیطی و فرآیندهای اکولوژیکی در مقیاسهای مکانی و زمانی مختلف عمل میکنند و قدرت و ماهیت ارتباطات گونه-محیط میتواند متفاوت باشد.
-
فرآیندهای محلی (Local-scale)، مانند تغییرپذیری ریزاقلیم (Microclimate)، تنوع رطوبت خاک یا میکروتوپوگرافی، میتوانند الگوهای دقیق حضور یا عدم حضور گونهها را شکل دهند.
-
در مقابل، الگوهای منطقهای یا جهانی اغلب توسط گرادیانهای اقلیمی وسیع، محدودیتهای پراکنش و زیستجغرافیای تاریخی شکل میگیرند.
بنابراین انتخاب وضوح مکانی و گستره مناسب برای مدلسازی ضروری است تا SDMها فرآیندهای اکولوژیکی مرتبط را بدون ایجاد آثار جانبی شناسایی کنند.
همچنین مقیاس زمانی مهم است: پراکندگی گونهها میتواند فصلی، بینسالی یا طی دههها تغییر کند، که استفاده از دادههای محیطی زمانبندی شده و مدلسازی دینامیک را برای پیشبینی تحت شرایط تغییر یافته ضروری میکند.
۲.۴ گرادیانهای محیطی (Environmental Gradients)
ادغام گرادیانهای محیطی در SDM یکی دیگر از اصول اساسی است.
-
گونهها به گرادیانهای پیوسته مانند دما، بارش، ارتفاع یا pH خاک پاسخ میدهند که اغلب الگوهای غیرخطی ایجاد میکند.
مثال: یک گونه ممکن است عملکرد بهینه در دماهای متوسط داشته باشد و بقا در هر دو حد پایین و بالا کاهش یابد. -
مدلهای افزایشی تعمیمیافته (GAMs) و سایر روشهای مدلسازی غیرخطی بهطور ویژه برای ثبت این پاسخهای پیچیده مناسب هستند.
درک موقعیت گونهها در طول این گرادیانها به اکولوژیستها کمک میکند تا:
-
حدود تحمل گونهها را استنباط کنند،
-
گلوگاههای احتمالی را شناسایی کنند،
-
و پیشبینی کنند که چگونه پراکندگیها ممکن است تحت تغییرات محیطی تغییر کند.
این نکته همچنین اهمیت انتخاب متغیرهای پیشبینیکننده اکولوژیکی مرتبط را برای نمایش دقیق گرادیانهای اصلی که بر حضور گونهها تأثیر میگذارند تأکید میکند.
۲.۵ پراکنش و اتصال (Dispersal and Connectivity)
پراکنش و اتصال، اصول اکولوژیکی دیگری هستند که پراکندگی گونهها را شکل میدهند و در SDM باید در نظر گرفته شوند.
-
حتی اگر شرایط محیطی در سراسر یک چشمانداز مناسب باشد، گونهها ممکن است به دلیل محدودیتهای توانایی پراکنش یا وجود موانعی مانند رودخانهها، کوهها یا مناظر دستکاریشده انسانی، مناطق خاصی را اشغال نکنند.
-
ادغام محدودیتهای پراکنش در SDMها میتواند پیشبینیها را بهبود بخشد، بهویژه هنگام پیشبینی تغییرات محدودههای آینده تحت تغییرات اقلیمی.
-
تکنیکهایی مانند مدلسازی اتصال (Connectivity Modeling) و سطوح مقاومت (Resistance Surfaces) میتوانند با SDMهای سنتی ترکیب شوند تا نگاهی واقعیتر به اشغال زیستگاه و الگوهای کلنیزایی ارائه دهند.
۲.۶ دینامیک گونهها و محیط (Temporal Dynamics)
نظریه اکولوژیکی همچنین بر اهمیت تعاملات پویا بین گونهها و محیط تأکید دارد.
-
بسیاری از پراکندگی گونهها توسط تغییرات زمانی در دسترسی به منابع، رژیمهای اختلال و نوسانات اقلیمی تحت تأثیر قرار میگیرد.
-
مثال: رویدادهای اپیزودیک مانند خشکسالی، سیلاب یا آتشسوزیها میتوانند بهطور موقت مناسب بودن زیستگاه را تغییر داده و بقای گونهها را تحت تأثیر قرار دهند.
-
SDMهایی که دینامیک زمانی را در نظر میگیرند، مانند مدلهای اشغال دینامیک یا لایههای اقلیمی زمانسری، میتوانند این فرآیندهای گذرا را بهتر ثبت کنند و قابلیت اعتماد پیشبینیها را افزایش دهند.
این نوع مدلسازی پویا بهویژه برای ارزیابی اثرات تغییرات اقلیمی یا تغییرات کاربری زمین بر پراکندگی گونهها ارزشمند است.
۲.۷ زمینه تاریخی و تکاملی (Historical and Evolutionary Context)
زمینه تاریخی و تکاملی برای درک پراکندگی فعلی گونهها ضروری است.
-
نوسانات اقلیمی گذشته، چرخههای یخبندان و رویدادهای زمینشناسی مسیرهای تکاملی گونهها را شکل دادهاند و بر توانایی پراکنش، تحمل فیزیولوژیکی و گستره زیستگاهها تأثیر گذاشتهاند.
-
ادغام دادههای محیطی گذشته و اطلاعات فیلوژنتیکی در SDMها به پژوهشگران اجازه میدهد محدودیتهای تاریخی را در نظر گرفته و ارزیابی کنند که چگونه محدوده گونهها در طول زمان تغییر کرده است.
این دیدگاه نه تنها درک اکولوژیکی را بهبود میبخشد، بلکه استراتژیهای حفاظتی را با شناسایی مناطقی که بهطور تاریخی پناهگاه بودهاند و ممکن است در آینده نیز نقش مشابهی داشته باشند، اطلاعرسانی میکند.
بخش ۳: منابع داده، پیشپردازش و ملاحظات کیفیت دادهها
دادههای با کیفیت بالا پایه و اساس مدلسازی قابل اعتماد پراکندگی گونهها هستند. دقت پیشبینی و ارتباط اکولوژیکی SDMها به کمیت، کیفیت و نمایش مکانی دادههای حضور گونهها و پیشبینیکنندههای محیطی وابسته است. دادههای حضور گونهها ورودی اصلی مدلها هستند، در حالی که متغیرهای محیطی زمینهای را فراهم میکنند که پراکندگی گونهها در آن تحلیل میشود. جمعآوری صحیح دادهها، پیشپردازش و کنترل کیفیت برای کاهش سوگیری، کاهش خطا و اطمینان از اینکه خروجی مدلها الگوهای اکولوژیکی واقعی را منعکس میکند ضروری است و نه فقط آثار محدودیت دادهها یا انتخابهای روششناختی.
۳.۱ دادههای حضور گونه (Species Occurrence Data)
دادههای حضور گونهها میتوانند به چند شکل باشند:
-
فقط حضور (Presence-only)
-
حضور-عدم حضور (Presence-Absence)
-
و دادههای فراوانی (Abundance Records)
دادههای حضور-تنها (Presence-only) رایجترین نوع هستند و معمولاً از مجموعههای تاریخ طبیعی، پایگاههای داده موزهها، بررسیهای میدانی یا پلتفرمهای علمی مردمی مانند Global Biodiversity Information Facility – GBIF و iNaturalist به دست میآیند. این دادهها مکانهایی که گونه مشاهده شده را ثبت میکنند، اما مکانهایی که گونه حضور ندارد را مشخص نمیکنند. دادههای حضور-تنها بهویژه برای گونههای کمیاب یا فراری مفید هستند، اما به رویکردهای مدلسازی خاص مانند MaxEnt نیاز دارند، که میتواند عدم وجود دادههای عدم حضور صریح را با ایجاد نقاط شبهعدم حضور (Pseudo-absence) مدیریت کند.
دادههای حضور-عدم حضور (Presence-absence) هم مکانهایی که گونه حضور دارد و هم مکانهایی که گونه در آنجا حضور ندارد را ارائه میکنند. این دادهها اطلاعات بیشتری نسبت به دادههای حضور-تنها دارند، زیرا به مدلها اجازه میدهند مستقیماً زیستگاههای مناسب و نامناسب را مقایسه کنند. معمولاً این دادهها از بررسیهای میدانی ساختاریافته، برنامههای پایش اکولوژیکی بلندمدت یا پروتکلهای نمونهبرداری استاندارد به دست میآیند. اگرچه دادههای حضور-عدم حضور دقت مدل را افزایش میدهند، اما در مقیاسهای بزرگ مکانی کمتر در دسترس هستند به دلیل چالشهای لجستیکی در نمونهبرداری منظم از مناطق وسیع.
دادههای فراوانی (Abundance Data) تعداد افراد در یک مکان مشخص را کمّی میکنند و داده غنیتری فراهم میآورند که شرایط محیطی را به تراکم جمعیت مرتبط میکند نه فقط حضور ساده. ادغام دادههای فراوانی در SDMها به مدلها امکان میدهد نه تنها مکانهایی که گونه میتواند زنده بماند را شناسایی کنند بلکه مکانهایی که در آن رشد و شکوفا میشود را نیز تشخیص دهند، و بینش دقیقتری از کیفیت زیستگاه ارائه دهند. با این حال، دادههای فراوانی نسبتاً کمیاب هستند و معمولاً نیازمند کار میدانی شدید هستند، بنابراین برای مطالعات محلی یا منطقهای مناسبترند تا مدلسازی در مقیاس جهانی.
۳.۲ پیشبینیکنندههای محیطی (Environmental Predictors)
پیشبینیکنندههای محیطی شرایط غیرزیستی و زیستی را توصیف میکنند که بر پراکندگی گونهها تأثیر میگذارند.
-
متغیرهای اقلیمی: مانند دما، بارش، رطوبت و فصلبندی. دادههای اقلیمی اغلب از دیتاستهای جهانی مانند WorldClim یا CHELSA به دست میآیند که لایههای مکانی با وضوح بالا از دادههای ایستگاههای هواشناسی تولید و با تکنیکهای ژئواستاتیستیک پیشرفته میانیابی شدهاند.
-
متغیرهای توپوگرافی: شامل ارتفاع، شیب و جهتگیری (Aspect) که بر ریزاقلیم، رطوبت خاک و تابش خورشید تأثیر میگذارند.
-
متغیرهای ادمیک یا خاکی (Edaphic Variables): مانند بافت خاک، pH و محتوای مواد مغذی، که بهویژه برای گیاهان و موجودات وابسته به خاک مهم هستند.
-
پوشش زمین و متغیرهای انسانی: در مناظر دستکاریشده توسط انسان اهمیت بیشتری یافتهاند، مانند شهریسازی، تراکم جادهها، تکهتکه شدن زیستگاهها و تغییرات کاربری زمین. فناوریهای فاصلهسنجی از راه دور (Remote Sensing)، مانند تصاویر ماهوارهای و عکاسی هوایی، لایههای داده ارزشمندی برای این پیشبینیکنندهها ارائه میدهند و تحلیلهای مقیاس بزرگ که عوامل طبیعی و انسانی را در نظر میگیرند ممکن میسازند.
انتخاب پیشبینیکنندههای اکولوژیکی مرتبط برای عملکرد مدل حیاتی است.
-
اضافه کردن متغیرهای غیرمرتبط یا با همبستگی بالا میتواند تفسیرپذیری را کاهش دهد، عدم قطعیت پارامترها را افزایش دهد و پیشبینیهای غیرقابل اعتماد تولید کند.
-
تکنیکهایی مانند ضریب تورم واریانس (Variance Inflation Factor – VIF) یا ماتریس همبستگی (Correlation Matrices) برای تشخیص همخطی و حذف پیشبینیکنندههای تکراری استفاده میشوند.
-
تمرکز بر متغیرهایی با اهمیت اکولوژیکی شناختهشده یا فرضی باعث بهبود هم دقت و هم قابلیت تفسیر SDMها میشود.
۳.۳ پیشپردازش دادهها (Data Preprocessing)
پیشپردازش دادهها مرحله حیاتی در گردش کار SDM است که تضمین میکند دادههای حضور گونه و محیطی سازگار، دقیق و مناسب مدلسازی باشند.
-
پاکسازی دادههای حضور شامل تأیید شناسایی گونهها، اصلاح مختصات جغرافیایی و حذف رکوردهای تکراری یا نادرست است.
-
اشتباه در شناسایی گونه، مختصات نادرست یا خطاهای تایپی میتواند سوگیری قابل توجهی در SDMها ایجاد کند و پیشبینیهای گمراهکننده تولید کند.
-
فیلترینگ مکانی (Spatial Filtering) تکنیک رایجی است که سوگیری نمونهبرداری را با کاهش تراکم نقاط در مناطق با نمونهبرداری زیاد کاهش میدهد. این اطمینان را میدهد که مناطق با بررسیهای زیاد بهطور نامتناسب مدل را تحت تأثیر قرار ندهند و پیشبینیها الگوهای واقعی اکولوژیکی را منعکس کنند.
لایههای محیطی نیز نیازمند پیشپردازش هستند تا سازگاری و دقت حفظ شود.
-
همه لایهها باید به یک وضوح مکانی، سیستم مختصات و گستره یکسان استاندارد شوند.
-
اختلاف در وضوح یا سیستم مختصات میتواند باعث ناسازگاری و خطا در هنگام همپوشانی دادههای حضور با متغیرهای محیطی شود.
-
از روشهای بازنمونهبرداری (Resampling) یا میانیابی (Interpolation) برای همسانسازی لایهها استفاده میشود، و دقت دادهها در این فرآیندها با دقت حفظ میشود.
رسیدگی به سوگیری نمونهبرداری بهویژه برای SDMهای حضور-تنها مهم است.
-
مشاهدات اغلب نزدیک جادهها، شهرها یا مناطق حفاظتشده متمرکز میشوند که میتواند سوگیری مکانی ایجاد کند و پیشبینیها را تحریف کند.
-
چندین راهبرد برای کاهش این سوگیری وجود دارد، از جمله فیلترینگ مکانی، وزندهی نقاط حضور یا استفاده از دادههای پسزمینه گروه هدف (Target-group Background Data) که نقاط شبهعدم حضور را در مکانهایی که برای تاکسونهای مشابه بررسی شدهاند نمونهبرداری میکند.
-
این روشها تضمین میکنند که پیشبینیهای SDM تحت تأثیر تلاشهای نمونهبرداری نامتقارن قرار نگیرند و ترجیحات واقعی محیطی گونهها را منعکس کنند.
۳.۴ ملاحظات زمانی و مکانی (Temporal and Spatial Considerations)
-
تراز زمانی (Temporal Alignment) بین دادههای حضور و پیشبینیکنندههای محیطی مهم است. شرایط محیطی ممکن است فصلی، سالانه یا دههای تغییر کنند، بنابراین ضروری است که لایههای پیشبینیکننده مطابق با دورههای زمانی جمعآوری دادههای حضور باشند.
مثال: استفاده از دادههای اقلیمی فعلی برای پیشبینی مدل ساخته شده از رکوردهای تاریخی بدون تطبیق زمانی میتواند پیشبینیهای گمراهکننده ایجاد کند، بهویژه اگر محدوده گونه یا شرایط محیطی تغییر کرده باشد. -
مقیاس مکانی نیز حیاتی است.
-
لایههای محیطی با وضوح کم برای مطالعات منطقهای یا جهانی مناسب هستند، در حالی که لایههای با وضوح بالا برای مدلسازی مناسب بودن زیستگاه محلی لازم است.
-
عدم تطابق مقیاس مکانی دادههای حضور و پیشبینیکنندهها میتواند باعث کاهش دقت مدل شود.
-
رویکردهای سلسلهمراتبی یا چندمقیاسی (Hierarchical / Multi-scale) که روابط گونه-محیط را در چند وضوح مکانی مدل میکنند، بهطور فزایندهای برای ثبت فرآیندهای محلی و منطقهای همزمان استفاده میشوند.
۳.۵ ارزیابی کیفیت دادهها (Data Quality Assessment)
ارزیابی کیفیت دادهها مرحله نهایی حیاتی در پیشپردازش است.
-
معیارهایی مانند پوشش مکانی، حجم نمونه و نمایندگی محیطی به ارزیابی کمک میکنند که آیا رکوردهای حضور و پیشبینیکنندهها برای پشتیبانی از مدلسازی قوی کافی هستند یا خیر.
-
در برخی موارد، گونههای نادر یا مناطق کمنمونهبرداریشده ممکن است نیاز به کار میدانی اضافی، نمونهبرداری هدفمند یا استفاده از تکنیکهای افزایش داده (Data Augmentation) داشته باشند.
-
تحلیل حساسیت (Sensitivity Analysis)، که مدلها با زیرمجموعههای مختلف دادههای حضور یا پیشبینیکنندهها اجرا میشوند، میتواند منابع احتمالی عدم قطعیت را شناسایی کرده و تصمیمگیری درباره کفایت دادهها را راهنمایی کند.
بخش ۴: رویکردها و الگوریتمهای مدلسازی
مدلسازی پراکندگی گونهها (SDM) بر روشهای آماری و محاسباتی متنوعی تکیه دارد تا رابطه بین حضور گونهها و پیشبینیکنندههای محیطی را کمّی کند. این رویکردها از مدلهای کلاسیک مبتنی بر رگرسیون تا الگوریتمهای پیشرفته یادگیری ماشین متغیر هستند، و هر کدام مزایا، محدودیتها و کاربردهای اکولوژیکی خاص خود را دارند. درک این روشها برای انتخاب چارچوب مناسب مدلسازی، تفسیر صحیح نتایج و اطمینان از دقت و معناداری اکولوژیکی پیشبینیها حیاتی است.
۴.۱ مدلهای خطی تعمیمیافته (Generalized Linear Models – GLM)
مدلهای خطی تعمیمیافته (GLM) از قدیمیترین و پرکاربردترین ابزارها در SDMها هستند.
-
GLMها رگرسیون خطی سنتی را گسترش میدهند و اجازه میدهند متغیر پاسخ از توزیع غیر نرمال پیروی کند و میانگین پاسخ به ترکیب خطی پیشبینیکنندهها از طریق یک تابع لینک متصل شود.
-
برای دادههای حضور-عدم حضور، توزیع دو جملهای (Binomial) معمولاً استفاده میشود و تابع لینک لوگیت (Logit) پیشبینیکنندهها را به احتمال حضور گونه متصل میکند.
فرمول ریاضی GLM برای حضور-عدم حضور:
logit(pi)=β0+∑j=1kβjXij\text{logit}(p_i) = \beta_0 + \sum_{j=1}^{k} \beta_j X_{ij}logit(pi)=β0+j=1∑kβjXij
که در آن:
-
pip_ipi = احتمال حضور در سایت iii
-
β0\beta_0β0 = عرض از مبدأ
-
βj\beta_jβj = ضرایب پیشبینیکنندههای kkk
-
XijX_{ij}Xij = مقدار پیشبینیکننده jjj در سایت iii
-
تابع لوگیت تضمین میکند که احتمال بین ۰ و ۱ باقی بماند.
GLMها به دلیل سادگی، قابلیت تفسیر و دقت آماری ارزشمند هستند.
-
به اکولوژیستها اجازه میدهند فرضیههای تأثیر عوامل محیطی خاص بر پراکندگی گونهها را آزمایش کنند.
-
محدودیت: GLMها فرض خطی بودن رابطه بین پیشبینیکنندهها و پاسخ را در مقیاس لینک دارند و ممکن است رابطههای پیچیده و غیرخطی سیستمهای اکولوژیکی را بهخوبی نشان ندهند.
۴.۲ مدلهای افزودنی تعمیمیافته (Generalized Additive Models – GAM)
برای رفع محدودیت خطی بودن در GLMها، مدلهای افزودنی تعمیمیافته (GAM) معرفی شدند:
-
GAMها امکان رابطههای غیرخطی بین پیشبینیکنندهها و حضور گونهها را فراهم میکنند.
-
در GAM، هر پیشبینیکننده با یک تابع نرم (Smooth Function) مانند اسپلاینها (Splines) تبدیل میشود:
logit(pi)=β0+∑j=1ksj(Xij)\text{logit}(p_i) = \beta_0 + \sum_{j=1}^{k} s_j(X_{ij})logit(pi)=β0+j=1∑ksj(Xij)
که در آن:
-
sjs_jsj = تابع نرم اعمالشده بر پیشبینیکننده XijX_{ij}Xij
مزیت GAM: توانایی ثبت پاسخهای پیچیده، اغلب تکاوج یا دارای آستانه، نسبت به گرادیانهای محیطی که در دادههای اکولوژیکی رایج است.
-
مثال: یک گونه ممکن است بیشترین حضور را در دماهای متوسط و کمترین حضور را در دماهای حدی داشته باشد—الگویی که GAMها به راحتی ثبت میکنند اما GLMها به سختی.
-
GAMها علاوه بر عملکرد پیشبینی بهتر، قابلیت تفسیر آماری را حفظ میکنند.
۴.۳ مدلسازی بیشینه آنتروپی (Maximum Entropy – MaxEnt)
MaxEnt یک روش فقط حضور (Presence-only) است که در SDMها بسیار محبوب است:
-
MaxEnt احتمال توزیع حضور گونه را به گونهای تخمین میزند که بیشترین یکنواختی (Maximum Entropy) را داشته باشد، در حالی که به محدودیتهای محیطی در نقاط حضور شناختهشده پایبند باشد.
-
مفهوم: MaxEnt نزدیکترین توزیع به یکنواختی در منطقه مطالعه را تعیین میکند با توجه به اطلاعات ارائهشده توسط دادههای حضور.
فرمول احتمال حضور در مکان xxx:
P(x)=1Zexp(∑jλjfj(x))P(x) = \frac{1}{Z} \exp \left( \sum_j \lambda_j f_j(x) \right)P(x)=Z1exp(j∑λjfj(x))
که در آن:
-
fj(x)f_j(x)fj(x) = ویژگیهای محیطی
-
λj\lambda_jλj = وزنهای برازش دادهشده برای بیشینه کردن احتمال
-
ZZZ = ضریب نرمالسازی (Normalization Constant)
مزایا:
-
مناسب وقتی که دادههای عدم حضور دردسترس یا قابل اعتماد نیستند.
-
توانایی مدیریت پیشبینیکنندههای همبسته، روابط غیرخطی و نمونههای کوچک.
-
محدودیت: حساس به سوگیری نمونهبرداری، بنابراین پیشپردازش دقیق و اصلاح سوگیری ضروری است.
۴.۴ جنگل تصادفی و درختان رگرسیون تقویتشده (Random Forest – RF و Boosted Regression Trees – BRT)
RF و BRT رویکردهای یادگیری ماشین مبتنی بر مجموعه (Ensemble-based) هستند:
-
RF: چندین درخت تصمیم (Decision Tree) با استفاده از زیرمجموعههای بوتاسترپ دادهها ساخته و نتایج را ترکیب میکند تا بیشبرازش کاهش یابد و دقت پیشبینی افزایش یابد.
-
BRT: درختها را بهصورت متوالی روی خطاهای باقیمانده درختهای قبلی میسازد و عملکرد مدل را بهطور تکراری بهبود میدهد.
ویژگیها:
-
میتوانند دادههای با ابعاد بالا و پیشبینیکنندههای همبسته را مدیریت کنند.
-
خودکار تعاملات بین متغیرها را شناسایی میکنند.
-
ارائه شاخص اهمیت متغیرها برای تعیین عوامل کلیدی محیطی.
-
محدودیت: پیچیدگی مدل میتواند قابلیت تفسیر را کاهش دهد و نیاز به اعتبارسنجی متقابل (Cross-validation) دارد تا از بیشبرازش جلوگیری شود، بهویژه وقتی حجم نمونه محدود است.
۴.۵ شبکههای عصبی مصنوعی (Artificial Neural Networks – ANN)
شبکههای عصبی مصنوعی (ANN) مدلهای محاسباتی الهامگرفته از ساختار مغز انسان هستند:
-
قادر به ثبت روابط بسیار پیچیده و غیرخطی هستند.
-
شامل لایههایی از “نورونهای” متصل که پیشبینیکنندههای ورودی را به خروجیهای احتمالی حضور یا مناسب بودن زیستگاه تبدیل میکنند.
-
وزنهای شبکه به صورت تکراری با فرآیند Backpropagation تنظیم میشوند تا خطای پیشبینی کاهش یابد.
مزایا:
-
بسیار مناسب برای گونههایی که پاسخ پیچیده به عوامل محیطی چندگانه دارند.
محدودیتها: -
اغلب “جعبه سیاه” هستند؛ روابط بین پیشبینیکنندهها و خروجیها تفسیر دشواری دارد.
-
نیازمند دادههای بزرگ و منابع محاسباتی قابل توجه.
۴.۶ مدلسازی مجموعهای (Ensemble Modeling)
مدلسازی مجموعهای پیشبینیهای چندین الگوریتم SDM را ترکیب میکند:
-
برای افزایش مقاومت مدل و مدیریت عدم قطعیت روششناختی.
-
مدلهای فردی ممکن است در فرضیات، حساسیت به کیفیت دادهها و توانایی ثبت روابط غیرخطی متفاوت باشند.
-
با ترکیب مدلها از طریق میانگینگیری، وزندهی یا روشهای اجماعی (Consensus Methods)، سوگیری مدلهای منفرد کاهش یافته و پیشبینیهای قابل اعتمادتر میشوند.
مزایا:
-
بهویژه مفید هنگام پیشبینی پراکندگی گونهها در شرایط اقلیمی آینده یا محیطهای جدید، که عدم قطعیت بالاتر است.
-
امکان کمیتبندی عدم قطعیت با مقایسه پیشبینیها بین مدلها و ارائه راهنمایی دقیقتر برای برنامهریزی حفاظت و ارزیابی ریسک.
۴.۷ انتخاب الگوریتم و بهترین روشها (Algorithm Selection and Best Practices)
انتخاب الگوریتم مناسب بستگی به:
-
دسترسی به دادهها، سوالات اکولوژیکی و قابلیت تفسیر مورد نظر دارد.
راهنمایی:
-
برای دادههای حضور-عدم حضور با روابط اکولوژیکی ساده: GLM یا GAM کافی هستند.
-
برای دادههای فقط حضور یا گونههای با پاسخهای پیچیده غیرخطی: MaxEnt یا روشهای یادگیری ماشین مانند RF و BRT توصیه میشوند.
-
مدلهای مجموعهای برای اکثر کاربردها به منظور افزایش قابلیت پیشبینی توصیه میشوند.
بهترین روشها:
-
پیشپردازش دقیق
-
انتخاب پیشبینیکنندههای اکولوژیکی مرتبط
-
کاهش سوگیری نمونهبرداری
-
اعتبارسنجی متقابل
-
ارزیابی واقعگرایی اکولوژیکی پیشبینیها
-
استفاده از چندین شاخص ارزیابی، مانند AUC، TSS و تحلیل حساسیت-ویژگی (Sensitivity-Specificity) برای اطمینان از پیشبینی دقیق حضور و شناسایی صحیح مناطق نامناسب.
۴.۸ جمعبندی
تنوع الگوریتمهای SDM ابزارهای قدرتمندی به اکولوژیستها ارائه میدهد:
-
GLM و GAM: قابلیت تفسیر و دقت آماری
-
MaxEnt: مدلسازی قوی فقط حضور
-
RF و BRT: ثبت روابط پیچیده و غیرخطی
-
ANN: مدلسازی تعاملات اکولوژیکی بسیار پیچیده
-
مدلسازی مجموعهای: افزایش دقت پیشبینی و ارزیابی عدم قطعیت
با انتخاب دقیق الگوریتمها و رعایت بهترین روشها، محققان میتوانند SDMهایی بسازند که هم از نظر اکولوژیکی معنادار و هم قابل اعتماد هستند، و بینش ارزشمندی برای حفاظت، سازگاری با تغییرات اقلیمی و مدیریت تنوع زیستی ارائه دهند.